

DX推進で不可欠な資産となる「データ」。生成AIをはじめとした新しい技術の登場により、データ活用への期待はさらに高まっている。これに伴い、近年はデータに基づく意思決定ができる組織とそうでない組織のパフォーマンスの差が拡大しているという。それでは「データを活用したDX」を実現する上で、失敗要因になっているものは何か。そしてその障壁をどう乗り越えればいいのか。DXとデータ活用に詳しい2人のキーパーソンが語り合った。
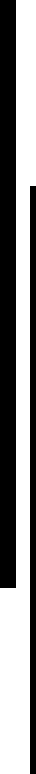
小さいPoCから始めると失敗しやすい?

デル・テクノロジーズ株式会社
UDS事業本部
本部長
五十嵐 修平氏
五十嵐 全世界でDXが急速に進む中、日本はその流れに取り残されているのではないか、という指摘が増えています。実際に数多くの企業への支援を行っている川上さんは、どのように感じていますか。
デル・テクノロジーズ株式会社
UDS事業本部
本部長
五十嵐 修平氏
川上 実際にPoC止まりで終わっているケースも多いのですが、逆に内製化を積極的に進めている企業や組織では、成功率が高くなっています。私が主に行っているのも内製化支援なのですが、業界で横のつながりがある方々からも、内製化でAI活用を成功させた事例を数多く聞いています。
生成AIを活用し、社内の問い合わせ業務を効率化した変革例はその1つです。具体的には、それまで人が対応していた問い合わせに対して、生成AIとRAG(検索拡張生成)によって社内データを活用し、回答を自動化しているのです。またカスタマーサポートでは、社内に蓄積されたVOC(顧客の声)を生成AIで分析し、満足度の高いお客様が何に満足しているのか、不満はどこから出てくるのか、という分析を行っているケースも登場しています。
もちろん生成AIはハルシネーション(事実ではない情報を生成してしまうこと)の不安があり、どこまでシステムに任せてどこを人がカバーするのかを、きちんと考えなければなりません。しかし生成AIを活用すれば、これまでの業務を大幅に効率化できます。
五十嵐 当社のお客様でも最近は、AI活用やデータ分析の成功事例が増えています。例えば自動運転では、私どものお客様であるSUBARU様のアイサイトの事例があります。以前は人がつくったアルゴリズムで状況判断を行っていたのですが、今はAIによって、よりスマートかつ柔軟な状況判断を実現しています。
海外では、米国テキサス州アマリロ市の事例もあります。同市は自然災害が多い地域なのですが、住民の多くが英語を話せない移民であるため、災害情報の伝達に課題がありました。その解決のため、生成AIを活用した「デジタルアシスタント」で、音声による多言語対応を行っています。
さらにデル・テクノロジーズ自身も、社内でのデータ活用を推進しています。AIも製品に組み込むだけではなく、社内業務での活用が進んでいます。様々な部門が意識的にユースケースを想定し、AIをどう活用すれば効率化できるのかを考えているのです。
DXの成否を大きく左右するリーダーの力量
五十嵐 このように数々の成功事例が出ている一方で、成果があがらないケースもあります。特にPoCを小さく始めたケースほど、失敗しやすいと感じています。

株式会社D.Force
代表取締役社長
川上 明久氏
データマネジメント業務の内製化、データベース全般の伴走型コンサルティングに多数の実績・経験を持つ。データベース関連の書籍やIT系メディア記事の執筆、セミナー・講演も多数手がける。データ活用の高度化、運用スタイル変更によるコスト削減などを通して、継続的に成果を上げる組織構築を支援している。
川上 確かに失敗パターンの1つに「小さなPoCからスタートする」というものがあると思います。PoCの検証範囲が狭いため、それだけ検証しても結果として分かることが限られてしまう、というケースです。
株式会社D.Force
代表取締役社長
川上 明久氏
データマネジメント業務の内製化、データベース全般の伴走型コンサルティングに多数の実績・経験を持つ。データベース関連の書籍やIT系メディア記事の執筆、セミナー・講演も多数手がける。データ活用の高度化、運用スタイル変更によるコスト削減などを通して、継続的に成果を上げる組織構築を支援している。
五十嵐 とりあえずは小さな成功を迅速に達成すればいい、という考え方は、アジャイルの本質を誤解しているといえますね。
川上 そうなってしまう最大の原因は、リーダーの力量が不足していることではないでしょうか。DXを成功させるには、「技術の目利きができる」だけではなく、それを「自社の業務にどう適用すれば変革につながるのか」、さらに「その先で何を目指すのか」というゴールまで見通せるリーダーが必要です。
五十嵐 最初にゴールをきちんと設定して、そこまでのステップを設計する必要があるわけですね。
川上 これができるリーダーがいないと、PoCの設計もうまくいきません。そのため長期的な視座がないままPoCを始めてしまい、結局はそれをほかの業務や部署に展開できない、という結果に陥るのだと思います。また、周辺の人々を巻き込める説得力や、コミュニケーション能力も不可欠です。日本の伝統的な企業は縦割り組織になっていることが多いため、このようなことを苦手とするリーダーも少なくないようです。
五十嵐 トップのコミットも重要ですね。これによって、予算も確保でき、組織も変革できるリーダーシップが可能になります。このようなリーダーシップを発揮できているケースとそうでないケースで、大きな差が生まれているわけですね。
川上 その通りです。DXはまず中間的な成果を出し、その上で全社へと展開させていく必要があるため、数年はかかる取り組みになります。そのためリーダーシップの有無が成果に直結するのです。そしてもう1つ、成果を大きく左右すると私が考えているのが「データの民主化」です。
IT部門の役割は事業部門への「伴走と統制」に
川上 「データの民主化」は、最近急速に注目度が高まっているキーワードで、IT系の企業だけではなく一般企業でも意識されるようになっています。これまでごく一部のエンジニアだけが行ってきたデータ分析を、事業部門のアナリストでも行えるようにしたいというニーズが、最近ではかなり増えているのです。
データの民主化によって、ビジネスや業務変革に向けたアイデアの芽が広がり、イノベーションのスピードは一気に加速します。先程、DXを推進するためのリーダーシップは日本企業が苦手なことだと述べましたが、これは逆に「現場が強い」日本企業にとって、かなり有利な方向性ではないかと考えています。
五十嵐 私もそう思います。日本企業には社内にデータを見て判断できる素養を持つ人が、数多くおられる。そういう意味でも「データの民主化」は、日本企業にとっての重要な戦略になると考えています。ただし日本では、自分の部署に閉じた「サイロ化したデータ分析」になりやすい、という点には注意すべきです。「データの民主化」を、会社全体でデザインしていく必要があるでしょう。
川上 おっしゃる通り、ツールだけを現場にポンと渡しても、適切に使えるとは限りませんね。どうすれば全体最適な使い方になるのか、誰かが指導しながら統制していかなければなりません。
五十嵐 その役割を、社内のどの部署が担うべきだとお考えですか。
川上 IT部門だと思います。従来のIT部門の役割は、ITツールを作成してユーザーに提供し、現場が受け入れた後は保守・運用を行う、というものでした。しかしこれからは、現場主導で正しく使ってもらうための「伴走」と「統制」が重要な役割になっていきます。これはIT部門にとって、チャレンジングな仕事になるはずです。
ただし、様々なテクノロジーが次々に登場する中で、すべてをカバーしながらこれらを行うのは簡単ではありません。外部の専門サービスの活用や、スタートアップや研究所とのオープンイノベーションを行える体制も必要です。それらの最適な組み合わせを考えることも、IT部門の重要な仕事になると思います。
DXのためのITツールは事業部門主導で利用することになるが、IT部門にはそのサポート役としての「伴走」と、
全社での最適化に向けた「統制」が求められるようになる
五十嵐 「伴走と統制」とは、的を射た表現ですね。私どもがお客様とお話をしているときも、IT部門の役割がどう変わってくるのか、という話題が増えています。
ITトレンドは「クラウド化」から「プラットフォーム」へ
川上 そこで重要になるのが「プラットフォーム」という考え方です。これまでIT部門の大きなテーマは「クラウド化」であり、クラウドで提供されている様々なサービスをどう選定して組み合わせるかが、重要な仕事の1つでした。しかしAIなどの先端技術は進歩が早すぎるため、それに一般企業が追随するのは大変です。そのため、システムコンポーネントを組み合わせて設計するのではなく、幅広い領域をカバーする「プラットフォーム」を選択し、技術進化への対応もプラットフォーム自体で自動的に行う方向に向かうことになるでしょう。
その1つが、データ分析やAI活用を行うためのデータ基盤です。最近ではSaaSの利用が増えており、それ以外にもデータが生成される場所が増えています。これらのシステムからデータを収集して活用できる状態にするには、数多くのデータ連携を行う必要があります。大企業ではその数が、1000本を超えることも珍しくありません。その結果、データサイエンティストの仕事の半分以上が、データのクレンジングや名寄せといった、前処理に費やされています。

システムコンポーネントを組み合わせて設計するのでは、技術の進化に追随することは困難になっていく
五十嵐 それではせっかくデータサイエンティストを育てても、その能力を生かし切ることができませんね。私どものお客様の中にも「データサイエンティストではなく『前処理スト』だ」と、自嘲的にお話する方もいらっしゃいます。
川上 このようなデータ連携をなくしていこうということで、最近では仮想化の技術が進みつつあります。データそのものを連携させるのではなく、その提供ポイントを仮想的に統合することで、すぐに使えるようにするのです。このようなプラットフォームがあれば、データサイエンティストの力量を最大限に発揮でき、貴重な存在であるエンジニアもより前向きなアクションに取り組みやすくなります。
五十嵐 デル・テクノロジーズでも、データ仮想化の取り組みを積極的に推進しています。「Bring AI to Your Data(AIをすべてのデータに)」というスローガンのもと、データの「Single Source of Truth(データそのものを統合して単一ソースにまとめること)」というアプローチだけではなく、「Single Point of Access(データを仮想的にまとめてアクセスポイントを集約すること)」というアプローチを行っています。
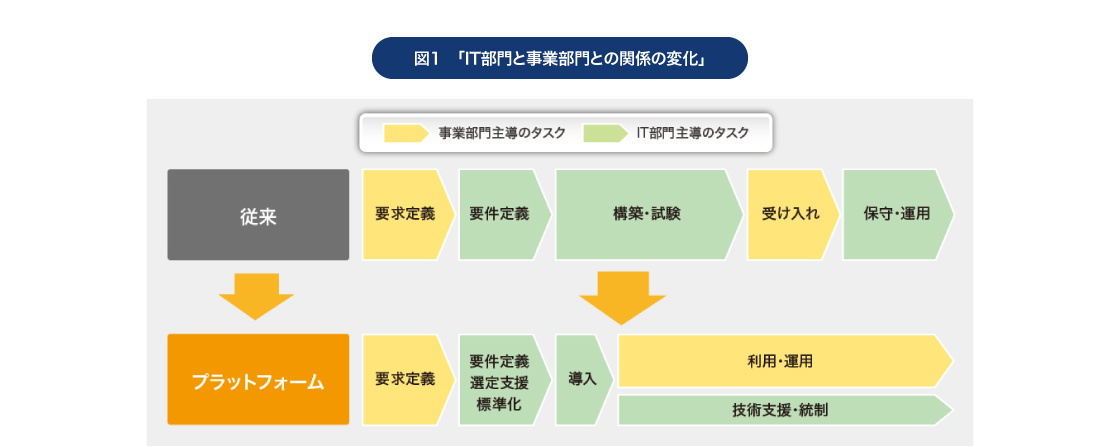
これをソリューションとして提供しているのが「Dell Data Lakehouse」です。デル・テクノロジーズでは、AI活用を成功させるための幅広いコンポーネント群をまとめ上げる「アンブレラ(傘)」として「Dell AI Factory」を提示していますが、Dell Data Lakehouseはその中の重要なコンポーネントの1つに位置付けられています。
データフェデレーション技術でデータを仮想統合
川上 具体的にはどのようにデータ仮想化を実現しているのですか。
五十嵐 複数のデータベースを「データフェデレーション」という技術で、仮想的に参照できるようにしています。その中核となっているのが、Starburst社の技術を活用した「Dell Data Analytics Engine」です。
Starburst社は分散型クエリエンジンのトッププロバイダーで、デル・テクノロジーズとは排他的なアライアンスをグローバルで結んでいます。日本でも、Starburst社の技術を提供できるのはデル・テクノロジーズだけです。
このアライアンスによって、独自の超並列処理を活用したクエリ(データの検索)の高速化を実現し、データソースからデータのコピーを行うことなく、スピーディかつ統合されたアクセスポイントを可能にしています。またクラウドやオンプレミス、エッジのデータソースを幅広くカバーしていることも、重要なポイントです。
Starburst社の技術を活用した「Dell Data Analytics Engine」によって、独自の超並列処理を活用したクエリの高速化を実現、
データソースからデータのコピーを行うことなく、スピーディかつ統合されたアクセスポイントを可能にしている
川上 このように仮想化プラットフォームは、データサイエンスやAI活用といった先端領域と、非常に相性がいいはずです。データサイエンティストの作業は探索的であり、アドホックにデータを追加しながら、様々な仮説を試す必要があるからです。これはデータ民主化を実現する上で、有効なソリューションの1つかもしれませんね。
五十嵐 川上さんがご指摘くださったメリットに加えて、さらに2つの重要ポイントがあります。1つは、Dell Data Lakehouseを導入するにあたってデータ統合が必要ないため、構築や管理が容易になることです。データそのものをデータレイクなどにコピーする「データ統合」は、膨大なデータをマージし、保存するための大規模なシステム構築が必要になります。またデータソースの追加や変更時には、周辺への影響を調査する必要があります。しかしDell Data Lakehouseならその必要はありません。
もう1つは、アクセスポイントを統合することで、プラットフォームの中に「統制」を組み込めることです。そのための管理機能も充実しており、コンプライアンスやセキュリティーを守りながら、データ民主化を進められます。
DXのコストは研究開発費と同じく将来のための必要経費
川上 データソースへの高速クエリでデータを仮想化しているので、リアルタイム性の高いデータ活用が容易というわけですね。
五十嵐 その通りです。データ連携では、連携のタイミングとデータ活用のタイミングでタイムラグが発生しますが、Dell Data Lakehouseならその問題も起きません。
川上 リアルタイムデータを意思決定につなげられるのは、大きなメリットだと思います。もちろん、データを準備する時間の削減が可能なことも重要です。実際にデータ連携が必要なデータ活用では、連携作業の負荷を下げるため、対象データを絞り込んでしまうケースが少なくありません。データ連携に膨大な時間がかかってしまうと、分析にかけられる時間が制約されてしまうからです。
しかしその結果、「小さく当てていこう」という意識が強くなり、意外性のある発見が難しくなります。そのため「そんなことはもう知っている」というレベルの成果しか得られず、次の展開につながりにくくなるのです。
五十嵐 Dell Data Lakehouseの提供に加えて、デル・テクノロジーズでは「AI Pursuit」というAI専門家チームも編成し、インフラと活用の両面からお客様のAI導入を支援しています。もちろんコンサルティングでも、これまで行ってきたデータ管理コンサルの延長として、お客様に寄り添ったサポートを行っています。
川上 データを活用するための人や組織と、その活動を支えるインフラとのバランスは大切ですね。この両輪を同時に回していくことで、データの民主化やAI活用、引いてはDXを成功させやすくなります。
もちろん最初はうまくいきませんし、お金もかかります。しかし数年我慢し、人材採用や育成に投資を続けることで、より大きな成果が得られるはずです。
DX推進は将来のための必要経費であり、研究開発費と同じようなものです。そこに近視眼的なROIを求めるのではなく、どのようなイノベーションを生み出したのかを評価すべきだと思います。

コラム
AI活用成功のためのアンブレラ
「Dell AI Factory」の概要と取り組み
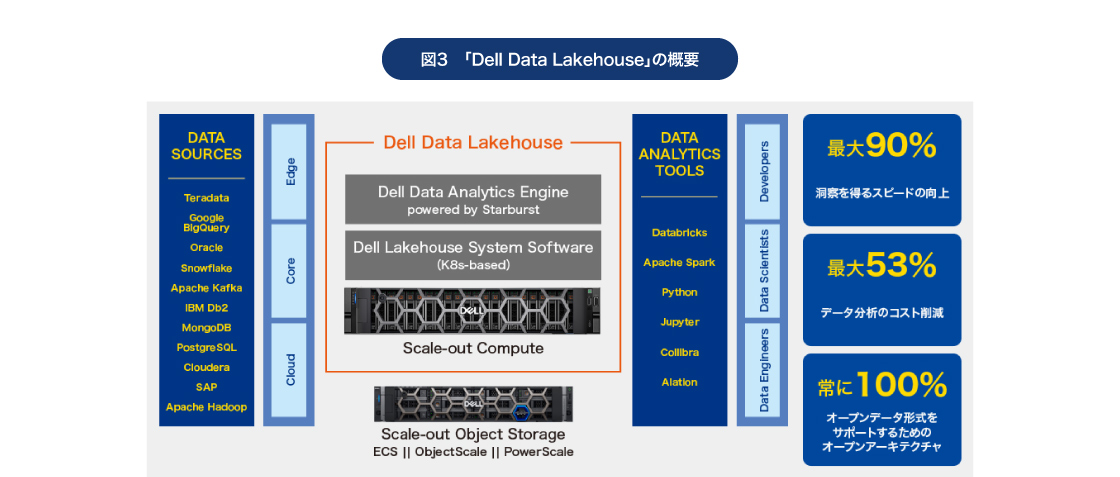
対談の中で登場した「Dell AI Factory」とは、生成AI導入時に直面する「複雑さがもたらすスキルと人材の問題」、「セキュリティやリスク」、そして「コスト」という、「3つの逆風」を解消するためのコンセプトである。生成AIにはあらゆるユースケースに適応できる万能なアプローチはなく、それ故に検討段階から複雑さに直面することになる。そして目指すユースケースに適した環境を用意しないと、コストが必要以上にかさんでしまう結果になりやすい。
これらを解決するための構成要素は、ユースケースの設定からそのために必要なデータ、システムインフラ、各種サービスと実に幅広い。そしてもう1つ注目すべきなのが、オープンなエコシステムによってその取り組みが進められているということである。その中でも重要なパートナーがNVIDIAであり、同社と共に「Dell AI Factory with NVIDIA」という取り組みを推進。その全体像を示したのが以下の図だ。
両社の技術を活用したインフラと、NVIDIAのAIソフトウエア、さらにデルのプロフェッショナルサービスを
組み合わせることで、生成AIの導入・活用を成功に導いていく
またデル・テクノロジーズが世界で初めて、NVIDIA DGX SuperPOD向けに検証された「イーサネットベースのストレージ」を実現していることも、注目すべき点だ。これを活用することで、生成AIの導入を簡素化・迅速化できるからだ。
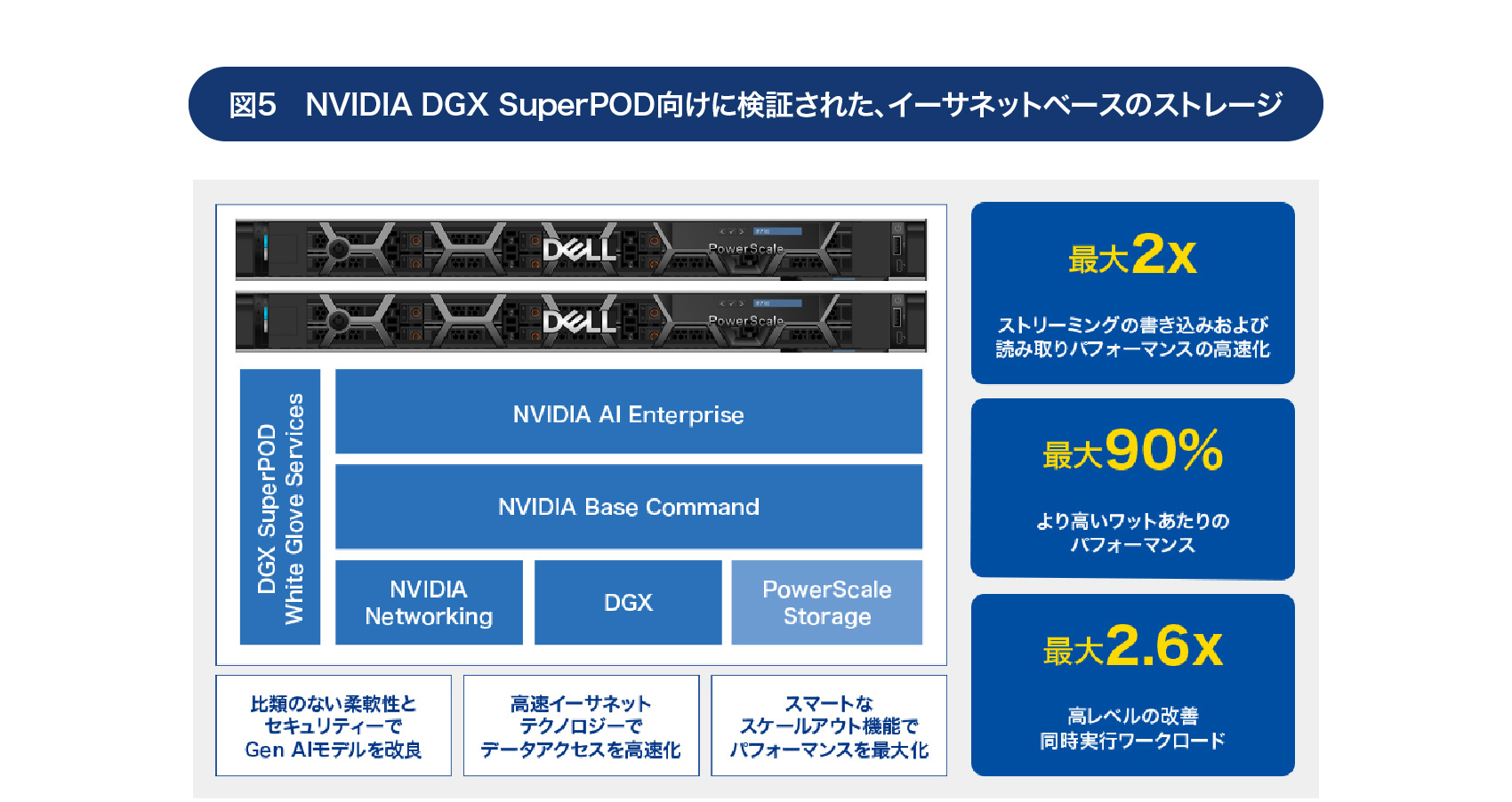
ファイバーチャネルではなくイーサネットでも、生成AIに適したストレージが可能であると実証したことは、
インフラを低コストかつ迅速に構築する上で重要だといえる
もちろん本文中で紹介した「Dell Data Lakehouse」の実現でも、NVIDIAとのパートナーシップは重要な役割を担っている。生成AI活用はもちろんのこと、全体的なデータ民主化を推進する上でも、大きな貢献を果たすことになるはずだ。

関連記事


