

AI活用が急速に進んでいる。しかし利用拡大に伴い、AIのインフラとなるGPUにまつわる課題も顕在化しつつある。具体的には、巨大な電力消費や排熱を勘案しつつ、いかに高性能GPUの潜在能力を引き出すか、が重要なポイントとなっているのだ。実際、インフラ構築で悩んでいる企業も少なくないはずだ。そこで参考にしたいのが、2024年10月の「Dell Technologies Forum Japan 2024」で行われた、GMOインターネットグループの講演である。この講演では最新技術を活用したGPUクラスタ構築の舞台裏が、赤裸々に明かされた。ここではその概要を紹介したい。
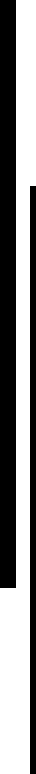
データセンターに運び込まれた数々のモンスターマシン

GMOインターネットグループ株式会社
システム統括本部
インフラ・運用本部
IaaSチーム リーダー
中村 槙吾氏
1995年にインターネット事業を創業したGMOインターネットグループ。“すべての人にインターネット”をコーポレートキャッチに、インターネットの場の提供に経営資源を集中し、インターネットをより豊かに便利にするべく、インターネットに関する様々な商材やサービスを提供。インターネットインフラ事業やインターネット広告・メディア事業、インターネット金融事業、暗号資産事業などを手掛けている。
同社では現在、生成AI開発や機械学習に最適化された国内最速級のGPUクラウド「GMO GPUクラウド」のリリースを着々と進めているところだ。「先日、相当な大きさの木箱が96個、弊社のデータセンターに搬入されました。その中身は『Dell PowerEdge XE9680』(以下、PowerEdge XE9680)です。サイズは6U、重量は113.3kg、最大消費電力1万1700kWというモンスターマシンです。これだけの大きさになると、もはや台車などは使いません。ハンドリフターという機器を使い、トラックからサーバールームまで運び込むことになります」とGMOインターネットグループ システム統括本部 インフラ・運用本部 IaaSチーム リーダーの中村 槙吾氏は話す。

データセンターに96台運び込まれたPowerEdge XE9680。NVIDIA H200 GPUを8枚搭載している
このサーバーで注目すべきは、重量や消費電力だけではない。ここに搭載されているGPUこそ重要なポイントだ。3958TFLOPSという圧倒的な計算能力を持つ「NVIDIA H200 Tensor コア GPU」が、1台に8枚も搭載されているのだ。
GPUのみならず、通信を司るNIC(Network Interface Card)も凄まじい性能を発揮する。今回搬入されたPowerEdge XE9680には「NVIDIA BlueField-3 SuperNIC」が8枚実装されている。これは1枚で400Gbpsの超高速通信が可能だ。
もちろんNICと接続されるネットワーク機器もモンスター級だ。今回は800Gbps✕64ポートを装備した「NVIDIA Spectrum-4スイッチ」が採用された。これによって、サーバーに搭載されているGPUとNICを1つずつひも付け、複数のサーバー間ですべてのGPUをインターコネクトする「NVIDIA Spectrum-X」という技術を実現、大規模な学習や計算を効率よく行える。
サーバー1台にNICが8枚あり、これが96台あるということは、接続のためのケーブルも膨大な量になる。その総延長距離は約40km。これは、東京都港区にあるグランドプリンスホテル新高輪から八王子駅までの距離に匹敵すると、中村氏は説明する。
物理的に動かすために行われた3つの施策
それではこのモンスター級のマシン群を動かすために、中村氏のチームは何を行ったのか。これらを効率的に動かし、潜在能力を最大限に引き出すため、大きく3つの取り組みを実施した。
1つ目は「設置」だ。前述のように、サーバー1台あたりの重量は113.3kg。これはオフィス向けの大型複合機とほぼ同じであり、簡単に持ち上げることはできない。筐体には取手がついているものの、これを人の手で持ってラッキングすることはほぼ不可能だ。そのため「サーバーリフト」という、サーバーを設置したい高さまで持ち上げる電動リフトを利用し、ラッキングを行った。
「このように重量級のサーバー設置はなかなか大変なのですが、PowerEdge XE9680にはスライドレールが採用されており、いったん設置したあとのメンテナンス性は極めて高くなっています。内部パーツを交換する際には、引き出すだけで交換作業を行うことができ、床降ろしを行う必要はありません。このメンテナンス性の高さには、非常に助けられています」と中村氏は話す。
2つ目は、GPUの活用からは切っても切り離せない「排熱」だ。PowerEdge XE9680の最大消費電力は1万1700Wであり、これは700Wの家庭用電子レンジを16台同時に動かすのと同電力量だ。H200 GPUを8枚装備すれば、そのうち5600WはGPUが消費することになる。そしてこの巨大な消費電力に伴い、膨大な量の熱が発生するわけだ。
ここで活用されたのが、デル・テクノロジーズが提供する管理ツール「iDRAC」である。iDRACで「どの負荷テストで」「どれだけの電力が消費されているのか」をきめ細かく測定。データがグラフでも表示されるため、傾向分析などが容易になったという。
これで傾向分析を行った結果、大きく2つの施策を行う必要があることが判明した
iDRACの管理コンソールで傾向分析を行った結果、効率的な冷却を行うには2つの物理的施策が効果的だと判明。1つは「排熱側の対向ラックを空にしておくこと」だ。PowerEdge XE9680は排気が強力であるため、その空気流を阻害しないようにしたという。もう1つは排気の風向きを変更すること。排気の流れを斜め上におよそ45度傾けるパーツをPowerEdge XE9680に追加し、サーバールーム天井にある熱の出口(換気口)に向けて、直接排熱の空気流が向かうようにしている。
2つの施策は効果てきめんだった。CFD(数値流体力学)シミュレーションで風の向きと温度を可視化し、施策の影響度を分析した結果、非常に高い効果をもたらしていることが確認できたという。
そして3つ目が「騒音対策」だ。PowerEdge XE9680の背面には手のひらサイズのファンが10基装備されており、発生する排気音の音圧は108dBに達する。これは自動車のクラクションとほぼ同じ音圧だ。しかもクラクションとは異なり、この騒音は継続的に鳴り続けている。つまりPowerEdge XE9680の背面で作業する人にとっては、ずっと耳元で自動車のクラクションを聞き続けているのと同じことになる。
何も対策を行わずに作業を行うと、一時的に耳が聞こえづらくなり、頭痛がすることもある。そのため今回は静音のために、イヤーマフを装着して作業を行うことにした。これで人体に対する騒音の影響を、かなり軽減できたという。
ベンチマークで実証されたNVIDIA H200 GPUとNVIDIA Spectrum-Xの威力とは
これらの施策によって、物理的にはモンスターマシンが動くようになった。しかしこれだけでは十分ではない。各機器の設定やOSなどの環境設定も行う必要がある。
「今回はNVIDIA Spectrum-Xのような最新技術を使用しているということもあり、最新技術のリファレンスや、最新技術がそもそもどのようなコンセプトで動いているのかなどを理解する必要がありました。また、これによってサービスを構築するには、どのような設定を行うことで最適化できるのかも考慮しなければなりません。そのため、公式のリファレンスを読み解き、公式のサポートを受け、最終的に検証環境を1つつくり上げて、様々な実証実験を行いました」(中村氏)
そうした実証実験の1つが「NVIDIA H100 GPU✕1台(NVIDIA H200 GPUの前世代モデル)」「NVIDIA H200 GPU✕1台」「NVIDIA Spectrum-Xで連携させたNVIDIA H200 GPU✕2台」という3種類の構成で行った、2つのベンチマークテストだ。
ベンチマークとしては「perfベンチマークGNNモデル」と、「Llama3-70Bファインチューニング時間」を利用。なおLlama3は2024年4月にMeta社が公開した生成AI「Llamaシリーズ」の最新モデルであり、Llama3-70Bは700億パラメーターを持つ、GPT-4とも比較されるLLMだ。
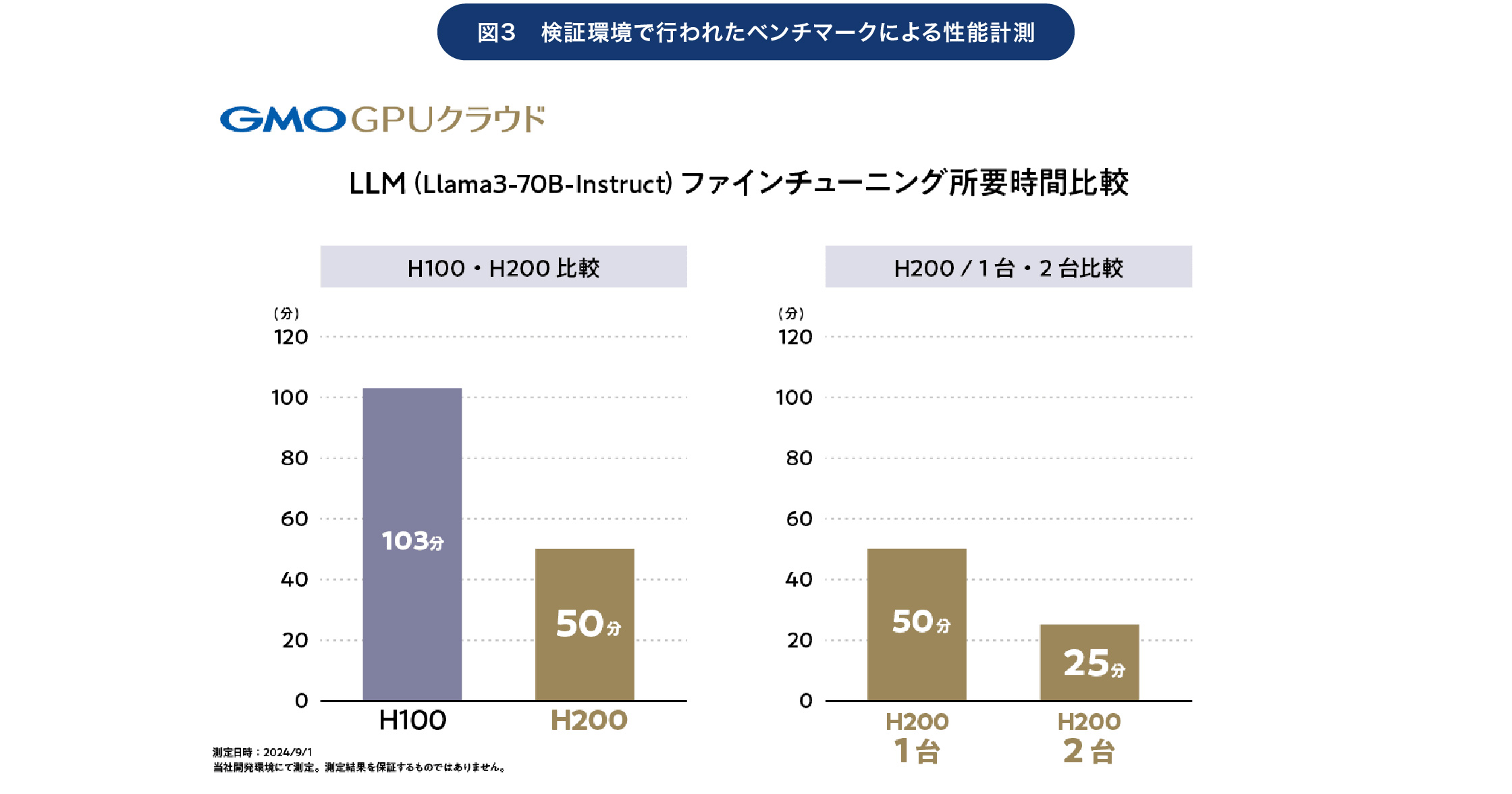
生成AIのトレーニングにおいて、NVIDIA H200 GPUとNVIDIA Spectrum-Xが大きな効果を発揮していることが分かる
この結果から分かるのは、「NVIDIA H200 GPUがNVIDIA H100 GPUに対して性能面で高い優位性を持っていること」と、「Llama3-70Bではその効果がより強く現れるということ」だ。またLlama3-70Bでは、NVIDIA Spectrum-Xの効果がさらに大きくなっていることも分かる。
苦労が大きい環境構築、専門サービス活用も有効な一手
「ここまでの話を聞くと、物理構築も機器設定も大変だと感じる人が多いかもしれません。しかしその苦労が不要なサービスを、GMOインターネットグループは2024年11月下旬にリリースします。それが『GMO GPUクラウド』です」(中村氏)
通常、生成AIの活用で利用される大規模環境には「GPUクラスタ設計」「ノード内・ノード間高速通信」「分散型ストレージ」という3つの要件が必要になるが、GMO GPUクラウドは、これらすべてを満たしている、と中村氏は説明する。
先述したように、GPUクラスタに関しては、NVIDIA H100 GPUの後継モデルであるNVIDIA H200 GPUを国内最速レベルで導入。ノード間の高速通信に関しては、NVIDIA Spectrum-Xを国内初採用している。
またジョブスケジューラーには、スーパーコンピューターや大規模なシステム開発で用いられる「Slurm」を採用。これにジョブを投げ込むだけで、超高速な並列環境を効率的に利用できるという。
「既に数多くのNVIDIA H200 GPUがデータセンターに設置されており、NVIDIA H200 GPUの性能をフルに発揮できるノードの提供が可能になっています。リリースは2024年11月下旬を予定しており、現在トライアルユーザーを募集しています」(中村氏)
最近は世界的にAIの活用が急拡大しており、GPUの需要も急増している。これに対して供給が追いついていない状況にあるといえるだろう。またインフラ環境をスクラッチから構築するには、GPUなどの設備導入に加えて、構築運用のためのノウハウやスキルにも巨額な投資が必要になる。GPUクラスタは単に環境構築をすればいいというものではなく、GPUの性能をフルに発揮できるネットワーク帯域なども重要になるからだ。
「生成AIの技術は日々進化しており、いち早く取り組み始めることで優位性を確保しやすくなります。『GMO GPUクラウド』を活用すれば、インフラ導入のハードルを回避しながら、素早く生成AIを使い始めることができます。生成AIのインフラ環境に課題を抱えているなら、ぜひ試していただきたい」と中村氏は最後に語った。

関連記事



関連リンクRelated Links