
「技術とビジネスをつなぎ社会を前進させる」をテーマとする「Intel Connection 2024 Tokyo」(2024年9月3日、9月4日)が開催された。今回は、インテルの掲げる「Bringing AI Everywhere」を基軸に、AIを生かした製品やソリューションを取り上げた。基調講演に加え、多数の分科会を実施。この中の1つで紹介されたのが「インテル® Gaudi® AIアクセラレーターの最新情報」だ。本格的なAI時代に向けて、AIアクセラレーターも投資対効果を重視する時代へ。生成AI/LLMの新たな選択肢が登場した。
AIに特化した設計により
価格性能比、拡張性、使いやすさを実現
様々なコンテンツを生み出す生成AI。業務プロセス変革やイノベーション創出など、ビジネスでの活用が進む。そして、その活用シーンが広がるほどに、膨大な計算処理が必要となる。しかし、限りある予算の中で高額なGPUですべてをカバーするのは、現実的ではない。生成AIの計算処理では、性能とともに投資対効果の観点がこれからは重要なポイントとなる。性能向上とランニングコスト低減の両方をいかに実現するか。その選択肢として、インテルが2024年後半に投入予定の「インテル® Gaudi® 3 AIアクセラレーター」(以下、Gaudi® 3)に注目が集まっている。システム開発パートナーに主要OEMメーカーが名を連ねており、市場が寄せる期待の大きさがうかがえる。
Gaudi® は、データセンター向けAIアクセラレーターだ。その特徴は大きく3点ある。
1つ目は、価格性能比。GPUと異なり、AIに特化した設計により、性能と効率性を徹底追求し、優れたコストパフォーマンスを実現している。昨今、大規模なクラスタを構築してAIを運用するケースも増えてきた。投資対効果の観点から価格性能比はますます重要となる。
2つ目は、拡張性。大規模かつ、さらに拡大する生成AI/LLM(大規模言語モデル)の処理要件に応えるために柔軟な拡張性を実現できる。ポイントは、オープンでコストパフォーマンスに優れたオンチップ・ネットワーキングであるという点だ。Gaudi® は、オンチップのEthernetを内蔵しており、大規模なクラスタを構築した場合も、別途NICを用意する必要がない。様々なベンダーのスイッチを使用できるなど、ロックインにとらわれることなく構築できる。設計の自由度の高さにより、企業の要望やニーズに合わせた柔軟な対応が可能だ。
3つ目は、使いやすさ。これまでGPUで開発していたモデルを、Gaudi® へ移行するのに、手間と時間を要しては実用的とは言えない。Gaudi® は、最小限のコード変更でGPUからのモデル移行、また新たなモデル構築が行なえる。

インテル® Gaudi® AI アクセラレーターは、AIに特化した設計により価格性能比、拡張性、使いやすさで新たな価値を提供する
Gaudi® シリーズの3世代目となるGaudi® 3は、3つの特徴にさらに磨きをかけ、大幅に進化した。現在販売中のGaudi® 2と比較した数字からも明らかだ。AI処理能力では、FP8(8ビット浮動小数点フォーマット)で2倍、Bf16(16ビット浮動小数点フォーマット)で4倍。ネットワーク帯域も100ギガビットから200ギガビットへ2倍。メモリー帯域も1.5倍となり、LLMの効率性とコストパフォーマンスが向上した。
ポイントは、優れた価格性能比を有しているという点だ。データサイエンス企業のDatabricksの調査によると、Gaudi® 2は推論処理において約1/2のコストでトークンを生成(AWS上のA100/H100搭載のインスタンスとの比較)。性能とコストを徹底追求した成果はすでに表れていた。
インテルは、広く利用されている大規模言語モデルを実行し、Gaudi® 3とNVIDIA H100の平均の推定パフォーマンスを比較(インテル調べ)した。1.5倍高速の学習処理、1.5倍高速の推論処理を発揮する。注視すべきは、1.4倍の電力効率で推論を実行できたこと。電気料金が高騰する中、電力コストの削減につながる。この比較は条件によって異なる結果となる可能性はあるが、参考情報として一見の価値があると言えるだろう。

第3世代インテル® Gaudi® 3 AIアクセラレーターは、学習処理、推論、電力効率で競合製品に勝る
ハードウエア面はもとより
ソフトウエア面の支援にも力を注ぐ
Gaudi® 3の構造的特徴は、2つのダイを1つのパッケージに実装しているという点だ。またプロセスノードをGaudi® 2の7nmから5nmに微細化し、演算能力やメモリー帯域幅の向上を図った。具体的には、32コアダイを2基、MME(行列演算エンジン)を8基搭載。HBM(High Bandwidth Memory)はGaudi® 2の96GBから128GBに増加。また200Gb Ethernetを24ポート備えることで、100Gb EthernetのGaudi®2からスケールアップ、スケールアウトの性能向上を図った。

会場内でGaudi® 3の実物を展示。多くの来場者が足を止めていた
経営層や情報システム部門の視点では、AIアクセラレーターの価格性能比は重視すべきポイントとなる。一方で開発者やユーザーにとって、様々なソフトウエアをスムーズに使えることは欠かせない要素だ。インテルでは、AIアプリケーション、フレームワーク、ライブラリなどオープンソースのソフトウエアスタックを用意している。
代表的な例をあげると、主要AIモデルへの対応、オープンソースの機会学習ライブラリPyTorch、AIプラットフォームHugging Face、高速化ライブラリDeepSpeed、オーケストレーションOpenShiftなどをサポートしている。また、API「Gaudi® ソフトウエア・スイート」の提供により数行のコード追加によりNVIDIAからモデルを移植しGaudi® 3で動かすことができる。新規開発はもとよりGaudi® 3を用いたAI開発環境への移行も容易に行える。
生成AIの開発期間を短縮する、インテル® Tiber™ デベロッパー・クラウドではGaudi® 2に加え、Gaudi® 3の提供を開始する予定だ。クラウドサービスとして、インテル®ソフトウエア開発ツールを使って、Gaudi® 3のワークロードを開発、テスト、実行できる、開発サンドボックス環境を提供。注目を集めるGaudi® 3を手軽に利用し開発できるメリットは大きい。また、コストパフォーマンス面でも優れており、AI開発環境の最適解と言える。
インテルは、AI開発におけるハードウエア面の支援はもとより、ソフトウエア面にも力を注ぐ。両面の支援により、ビジネスや暮らしの中で生成AIによる新たな価値創造に貢献していく。
パネル展示ではAIアプリケーションを使ったデモも実施
「Intel Connection 2024 Tokyo」では、Gaudi® 3のパネル展示において、現行Gaudi® 2上でLLMのレスポンスを体験できるデモを行なっていた。LLMによるテキスト生成に、外部情報の検索を組み合わせ、回答精度を上げる技術RAG(Retrieval-Augmented Generation)では、テキストに合わせて関連動画を選択するデモを実施。ほかにも、3Dモデルの自動生成、チャットなど、大規模モデルがGaudi® 2の環境でスムーズに動くことがわかった。
OEMメーカーはGaudi® 3の性能評価を開始しており、性能面はもとよりソフトウエアに関しても使いやすいとの評価をもらっているとスタッフは説明を加えた。

デモを交えたGaudi® 3のパネル展示
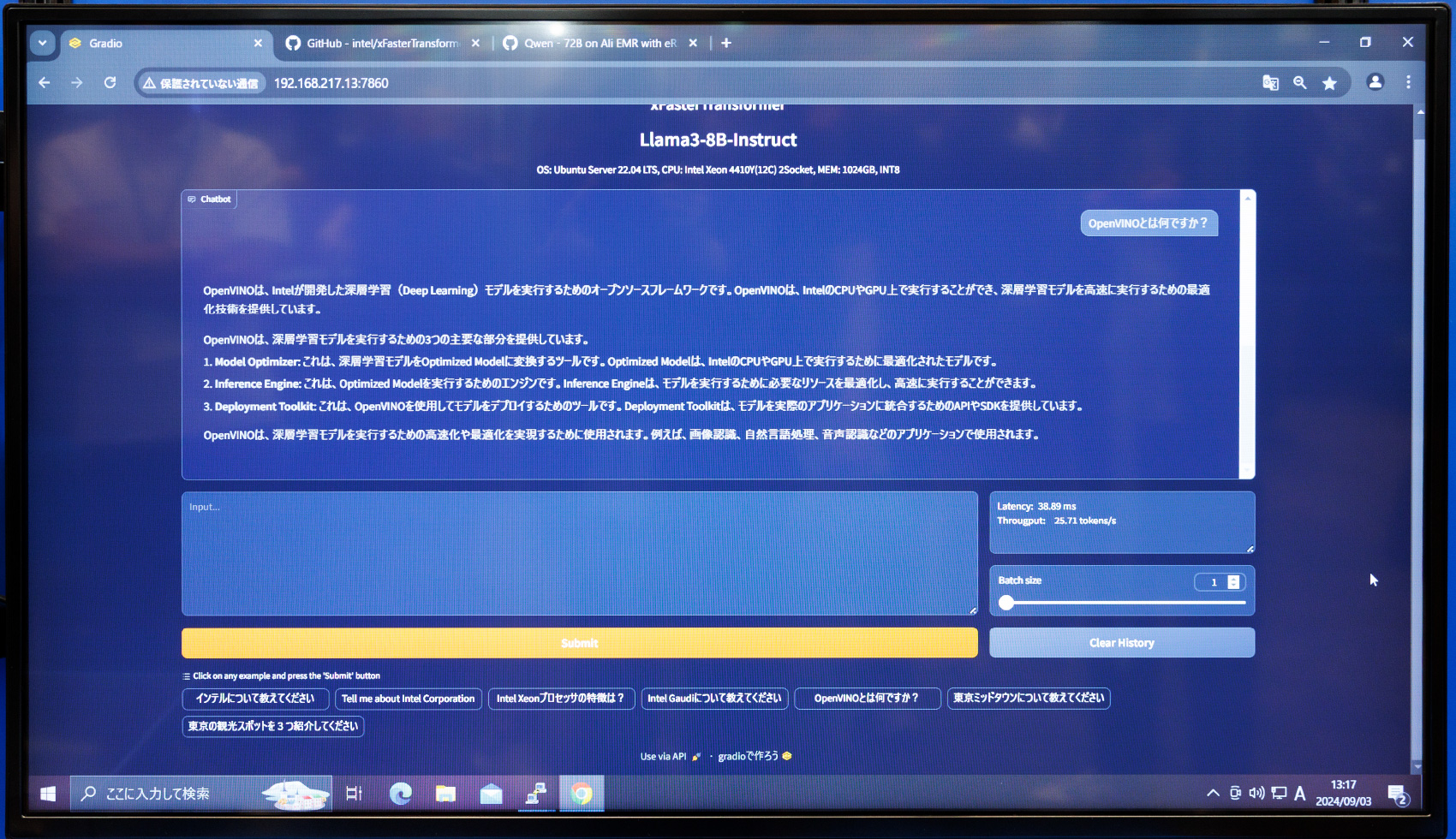
大規模モデルがGaudi® 2の環境でスムーズに動くことを実証
2024年末、OEMメーカーから
Gaudi® 3搭載サーバーが次々と市場投入
Gaudi® 3はAI専用アクセラレーターだけあって、NVIDIA H100よりも、「学習処理」、「推論」、「電力効率」で優位性を持つ。優れた価格性能比や、コストを抑えて拡張できる点は、大規模なクラスタ構築のニーズに応える。AI推論において、RAG、チャットなどの用途を検討している企業ではGaudi® 3は有力な選択肢となる。また学習処理では、投資対効果を重視する場合に、Gaudi® 3を検討するケースも増えるだろう。さらに中堅・中小企業では、優れた価格性能比によりAI用途で利用しやすくなる。2024年にサンプル供給を開始してまだ間もないが、海外では大規模案件で採用が決まった。日本でも「検証してみたい」という要望が多数寄せられている。
重要なポイントは、NVIDIA製品からの移行も容易に行えるということ。AIを使って競争力を高めるためには企業のニーズや目的に合わせて、GPUやAIアクセラレーターを適材適所で利用することが必要となる。供給面からも選択肢が広がることは、生成AIの発展につながる。
2024年末、OEMメーカーからGaudi® 3 搭載サーバーが次々と市場投入される。Gaudi® 3はコストと性能の徹底追求により生成AIの活用シーンを広げる。まさに本格化するAI時代を支える最適解かつ現実解と言えるだろう。