

従業員を支援するAI活用から、業務に組み込まれたAIへ。いまAIの実装は新たなフェーズに入りつつある。既に技術面ではこれが可能な状態になっており、そのPoCを進めている企業も多いはずだ。しかしPoCは成功したものの、業務への実装がなかなか進まないケースは珍しくない。それはなぜなのだろうか。
ここでは多くの日本企業が直面している「4つの壁」を明らかにするとともに、それらを乗り越えるための処方箋を示したい。
<この記事でわかること>
・AI PoCが業務実装に進まない背景には、日本企業に共通する「4つの壁」が存在する
・AIエージェント活用の障壁となる社内データのサイロ化は、仮想統合によって解決できる
・「AI in a Box」により、オンプレミスでのAI基盤構築にかかる期間を数週間にまで短縮できる
<目次>
・「デジタル労働力」の実装が進まない理由 ・【第1の壁】LLMの進化が招くリソース・コスト急増 ・【第2の壁】社内データの分散化・サイロ化 ・【第3・第4の壁】AI主権/データ主権とインフラ環境整備 ・よくある質問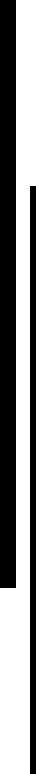
「デジタル労働力」の実装が進まない理由
業務遂行を効率化するために、従業員が日常的に生成AI(LLM)を活用している企業は、既に珍しい存在ではなくなった。現在もLLMの進歩は急速に進みつつあり「十分に実用的な段階に入っている」と感じている方も多いはずだ。
その使われ方は、いま大きな転換期に入りつつある。これまでは従業員の質問に回答するチャットや、議事録の作成や要約といった領域で使われることが多かったが、AIエージェントの登場によって「業務の中にAIを組み込み自律的に作業させる」といった考え方を具現化できるようになったのだ。
こうした「デジタル労働力」の実装が進めば、業務の効率が一気に高まるとともに、従業員は「人間が行うべき仕事」により専念できるようになるだろう。既にこのような世界の実現を目指し、PoC(概念実証)を進めている企業も少なくない。しかし、その多くがPoCで止まってしまい、業務への実装はなかなか進んでいないようだ。
その理由は大きく「4つの壁」があるからだ。
【第1の壁】LLMの進化が招くリソース・コスト急増
まず1つ目は「LLM自体が急速に進化したことで、必要なリソースも急増していること」。そもそもLLMの能力がここ数年で一気に向上した背景には、より多くのリソースを投入すればLLMの能力もそれに比例して増大するという「スケーリング則」が存在する。2020年には「Scaling Laws for Neural Language Models」という論文が発表されており、多くの生成AI開発企業はこれに基づいて、自社のAIの能力強化を推進してきたわけだ。
しかしこの状況は、AIの業務適用を阻害する要因になっている。必要な能力を確保するには、それに見合うハードウエアへの投資が求められるからだ。また最近では、LLMをクラウド型で提供している複数の企業が、AIサービス拡充のためにデータセンター建設の激しい競争を繰り広げている。これに伴いGPUやメモリといった基幹部品の需給がひっ迫しており、これもコスト増につながっている。
「最近はLLMが『リーズニング(推論)』機能を備え、論理的に思考するようになったことで、計算負荷が激増しています。さらにGTC 2026でも語られた通り、常駐型エージェント同士が自律的に対話・協調して業務をこなすようになったことが、推論時にかかる計算リソースを文字通り『爆発的』に押し上げているのです」と、エヌビディアの津田 恵理子氏は指摘する。

エヌビディア合同会社
エンタープライズ事業本部
ソフトウェア ビジネスデベロップメント
シニアマネージャー
津田 恵理子氏
この問題を解決するため、エヌビディアは「効率性を重視したLLM」の開発を推進しているという。エヌビディアといえば、生成AIの学習や推論に欠かせないGPUのメーカーとして有名だが、同社はハードウエアだけを提供しているわけではない。その上で動くソフトウエアやLLMに関しても、先進的な製品を数多く提供している。その1つとして津田氏が挙げるのが「NVIDIA Nemotron™」である。
「NVIDIA Nemotronは、効率的で高精度かつ専門的なエージェント型AIシステムを構築できるようにする、オープンモデル、データセット、テクノロジーのファミリーです。学習データやレシピなどはすべて公開されており、企業が安心して使うことができる上、そもそもの仕組み自体も大幅に進化しています。従来のLLMは主に『Transformer』という仕組みを使っていますが、2025年8月に発表した『NVIDIA Nemotron Nano 2』は、『Mamba』という新技術とTransformerを組み合わせているのです」(津田氏)。
NVIDIA Nemotronで「第1の壁」を突破
従来のTransformerが「入力データの長さの2乗に比例して計算量が増える」のに対し、Mambaは「1乗に比例」する。つまり入力データの長さが2倍になった場合、Transformerは計算量が4倍になるのに対し、Mambaは2倍にしかならないのである。これによってNVIDIA Nemotronは、トップクラスの精度を実現しながら、最大6倍のスループットを達成することに成功している。
またLLMが最終的な回答を生成する前の思考時間をユーザーが制限できる、「思考バジェット」という機能も装備。これによってLLMが「考えすぎる」ことを防止しているが、これも効率性の高さに貢献している。
「エヌビディアの日本の技術者がチューニングした小型モデルも公開しており、日本のLLM評価リーダーボード『Nejumi Leaderboard 4』において1位を獲得しています(※)。これもオープンソースの同規模モデルと比較して最大6倍のスループットを実現しており、小規模なエッジGPUで動かすことも可能です」(津田氏)
さらに2026年3月には、1200億パラメータの「NVIDIA Nemotron 3 Super」も発表。推論時にアクティブになるパラメータを10分の1に抑えることで、極めて効率的に推論を行うことが可能だと説明する。実際に第三者機関からも、同規模のモデルのなかでは「トップクラスの精度と効率性、オープン性を兼ね備えたモデル」であると評価されている(図1)。
横軸の「スループット」と、縦軸の「知性」のいずれにおいても、NVIDIA Nemotron 3 Superが高い数値を叩き出していることが分かる
推論環境を5分で立ち上げる「NVIDIA NIM™」
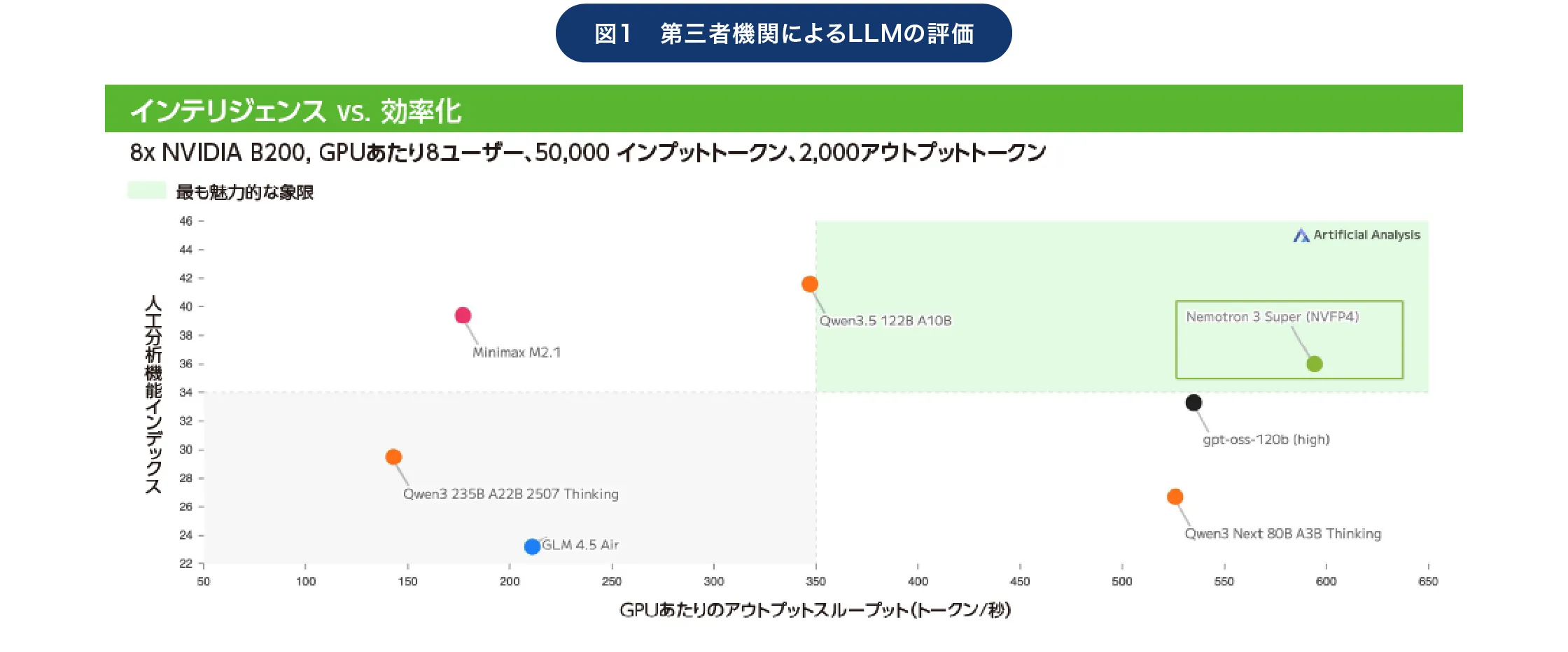
エヌビディアがソフトウエア領域で取り組んでいるのは、NVIDIA Nemotronのような生成AIモデルの開発・提供だけにとどまらない。生成AIモデルを高速かつセキュアに実装するための「NVIDIA NIM」という仕組みも提供している(図2)。
「NVIDIA NIMは、LLMなどのAIモデルをGPU最適化された状態でAPIとして即利用できるようにした推論マイクロサービスであり、Dockerコンテナとして提供されています」と津田氏。これを起動すると、実行しているハードウエアを検出した上で、GPUに最適化されたモデル/業界標準のAPI/メトリクスやログを出力する仕組みなどがセットで立ち上がり、すぐに本番利用できる状態になる。つまり環境の構築やライブラリの依存関係の調整、GPUの設定といった面倒な作業を行うことなく、短時間で推論環境を動かせるわけだ。
特定のLLMに最適化されたコンテナイメージであり、これを起動するだけでLLMの実行に必要な環境が整う。そのため短時間で推論環境を動かすことが可能だ
「もし同じことを手作業で行う場合には数日かかることもあるはずですが、NVIDIA NIMならわずか5分でデプロイできるのです」(津田氏)
※ 10B未満のモデルカテゴリにおいて、2026年2月17日に1位を獲得。
【第2の壁】社内データの分散化・サイロ化

Cloudera株式会社
Solutions Engineering Manager
吉田 栄信氏
NVIDIA NemotronやNVIDIA NIMを活用することで、ハードウエアリソースへの投資を抑えながら、簡単に推論環境を立ち上げることが可能になる。しかしLLMだけが動けばいいというものではない。自社の業務に特化したAIを実現するには、そのためのデータをLLMに与える必要があるからだ。
「一般的なLLMが学習しているのは、インターネットに存在する一般知識に過ぎません。企業にとって真に価値のあるデータは、組織内にある事業ドメイン固有の情報です。これこそが、その企業の競争優位性の源泉となります」と語るのは、Clouderaの吉田 栄信氏だ。
しかしここで、第2の壁が立ちはだかる。それは、多くの日本企業ではデータが分散化・サイロ化している点だ。
「エージェント型でAIを活用するには、全社データを横断的に理解させる必要があります。しかし実際には、必要なデータは部門ごとに閉じており、複数のクラウドを利用している企業の場合にはクラウドごとに分断されています。このままでは必要なデータをAIに届けることは極めて困難です。またデータ管理も複雑になり、その負担も大きくなってしまいます」(吉田氏)
ただし、データが分散していること自体は「失敗」ではなく、ビジネスの進化に伴う必然的な結果ともいえる。複数のシステムが存在するのは用途ごとに最適化された結果であり、マルチクラウドが一般的になったのはサービス特性に応じて使い分けた結果であるとともに、ベンダーロックインを回避するための有効なアプローチでもあるからだ。
「ここで問題なのは『分散していること』そのものではなく、『分散していることを前提に設計されていないこと』なのです。データが分散していることを前提にすれば、解決に向けたアプローチも自ずと明確になります」と吉田氏は説く。
Clouderaが提唱する「3つのAnywhere」
この解決に向けClouderaは、3つの「Anywhere」として提唱している。
第1は「CLOUD Anywhere」。分散したデータの管理負担が大きいのは、管理方法も「サイロ化」されているからだ。この問題を解決するには、「統一的なクラウド体験」で管理できるようにすればいい。
第2は「DATA Anywhere」。AIが社内の全データにアクセスできるようにするには、何らかの形で「統合アクセス」できる環境をつくればいい。
そして第3が「AI Anywhere」。これはデータのあるその場所で「安全に」AIを動かすことを意味する。
Clouderaのソリューションで 「第2の壁」を解決
Clouderaはこれら3つのAnywhereを実現するための様々なソリューションを提供している。「Cloudera Anywhere Cloud」というハイブリッド型のデータ&AIプラットフォームはその1つ。これによって、データやAIがどこにあっても、一貫した方法で管理することが可能になる。
また「Cloudera SDX(Shared Data Experience)」を核とした「Cloudera」のデータ&AIプラットフォームによって、どこにあるデータにもアクセス可能にしている。さらに「Cloudera AI Inference Service」によって、開発環境から独立したガバナンスの効いた環境で、安全な形でLLMを業務実装できる仕組みを提供している。
それらの中でも、AIによるデータアクセスに大きな貢献を果たすのが、DATA Anywhereを実現するClouderaだ。
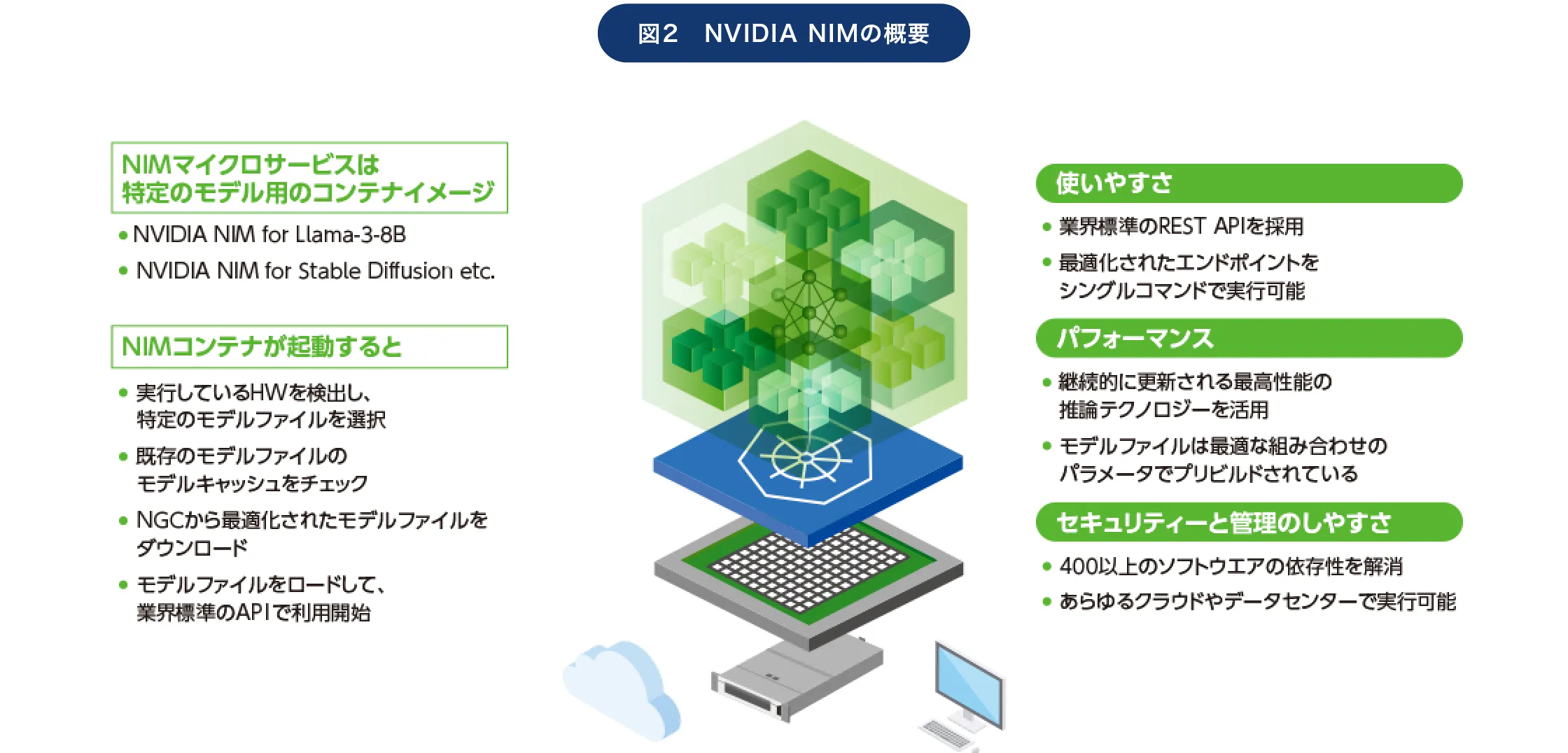
その基本的な考え方は「データを移動するのではなく接続する」というもの(図3)。全社データを利用可能にするには「データレイクなどにデータを集約する」という考え方になりがちだが、これではデータのリアルタイム性が低下し、元データがクラウドにある場合にはデータ転送のコストもかかってしまう。これらの問題を解決するには、実際にデータそのものを移動するのではなく、各データへのアクセス制御を一元管理することで「仮想的な統合」を行うのが効果的だ。
様々な場所にあるデータを仮想統合することで、データを「移動」することなく「接続」可能にする
「これによってデータの『場所』を問わずに活用・管理することが可能になります。またClouderaのソリューションには『多次元データリネージ』という、高度なデータ追跡機能も用意されており、複雑に連携するデータパイプライン全体を可視化できます」(吉田氏)
これに加えて、Cloudera AI Inference Serviceの存在も、AIを業務実装する際には重要な役割を果たすという(図4)。
「Clouderaによってあらゆるデータを活用可能にできますが、できれば『データがある場所にAIを置く』べきだと考えています。これを可能にするのがAI Anywhereであり、さらにCLOUD Anywhereによって、1つのコンソールから様々な場所にコンテナ環境をデプロイ可能にしています。なおCloudera AI Inference ServiceにはNVIDIA NIMのマイクロサービスも統合でき、NVIDIA Nemotronをはじめとする様々なLLMを『Cloudera AI Model Registry』でライフサイクル管理することも可能です」(吉田氏)
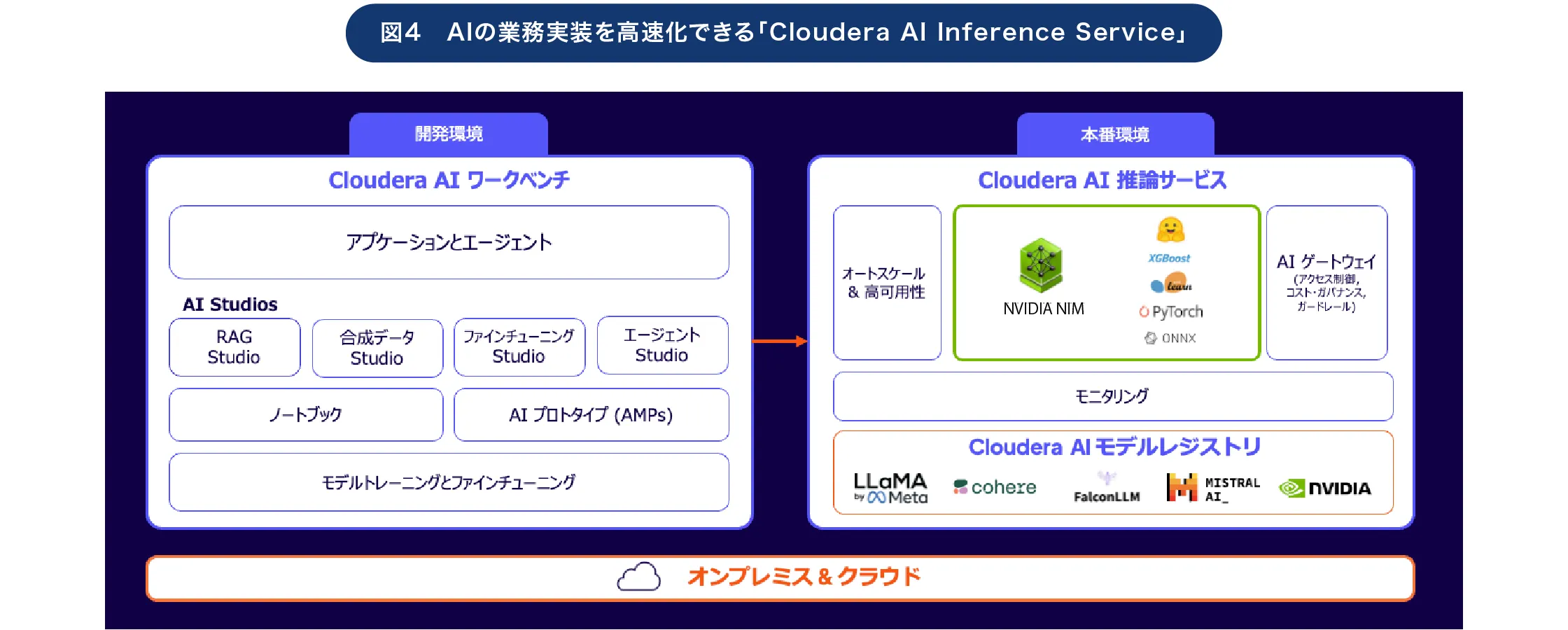
開発環境とは完全に独立した環境によって、ガバナンスの効いた安全な形でLLMを実装・稼働させることが可能だ
【第3・第4の壁】AI主権/データ主権とインフラ環境整備

デル・テクノロジーズ株式会社
AIプラットフォーム・ソリューションズ本部(AIP)
本部長/Country Leader
堀田 鋭二郎氏
ここまでで、AIが必要とするリソースの削減と、そのAIにデータを提供する方法は実現可能になった。次に立ちはだかるのが「AI主権/データ主権」という3つ目の壁だ。
社内データとそれを活用するAIは今後、企業競争力の重要な源泉になる。そのため「社外に持ち出すことは避けるべき」という考え方が広がっていくだろう。つまり「重要なデータとAIは社内に実装すべき」なのである。AIの業務実装が進んでいけば、このような「ソブリンAI」が主流になっていくはずだ。
ソブリンAIを実現するには、データ管理・アクセス環境とAI実行環境を、社内または国内のデータセンターに置くことが求められる。つまり、現在多くの企業が行っている「クラウド型AIサービスの利用」ではなく、「プライベートAI」へとシフトする必要があるのだ。そのためには社内にインフラ環境を整備しなければならないが、これは決して容易なことではない。
「AIの世界は利用すべきツールや検討事項が多岐にわたります。このようなソフトウエア環境に最適なハードウエアインフラも、幅広い選択肢の中から最適なものを選ぶ必要があります」と語るのはデル・テクノロジーズの堀田 鋭二郎氏だ。
「例えば開発環境と推論環境では求められるスペックが大きく異なり、推論環境の中でも業務内容や実装場所によって、必要なインフラは異なります。このようなインフラ環境をどう整備するかが、4つ目の壁になります」(堀田氏)
「AI in a Box」で 第3・第4の壁を突破
この第3、第4の壁を解消するため、エヌビディアとCloudera、そしてデル・テクノロジーズの3社が共同で提供しているのが「AI in a Box」だ。
エヌビディアとデル・テクノロジーズは以前から「Dell AI Factory with NVIDIA」という枠組みのもと、生成AIの設計・導入・運用を高速化する包括的なAIインフラストラクチャソリューションを提供しており、既に3000社を超える顧客が活用している。ここにClouderaも参画することで、AI in a Boxを実現しているという。
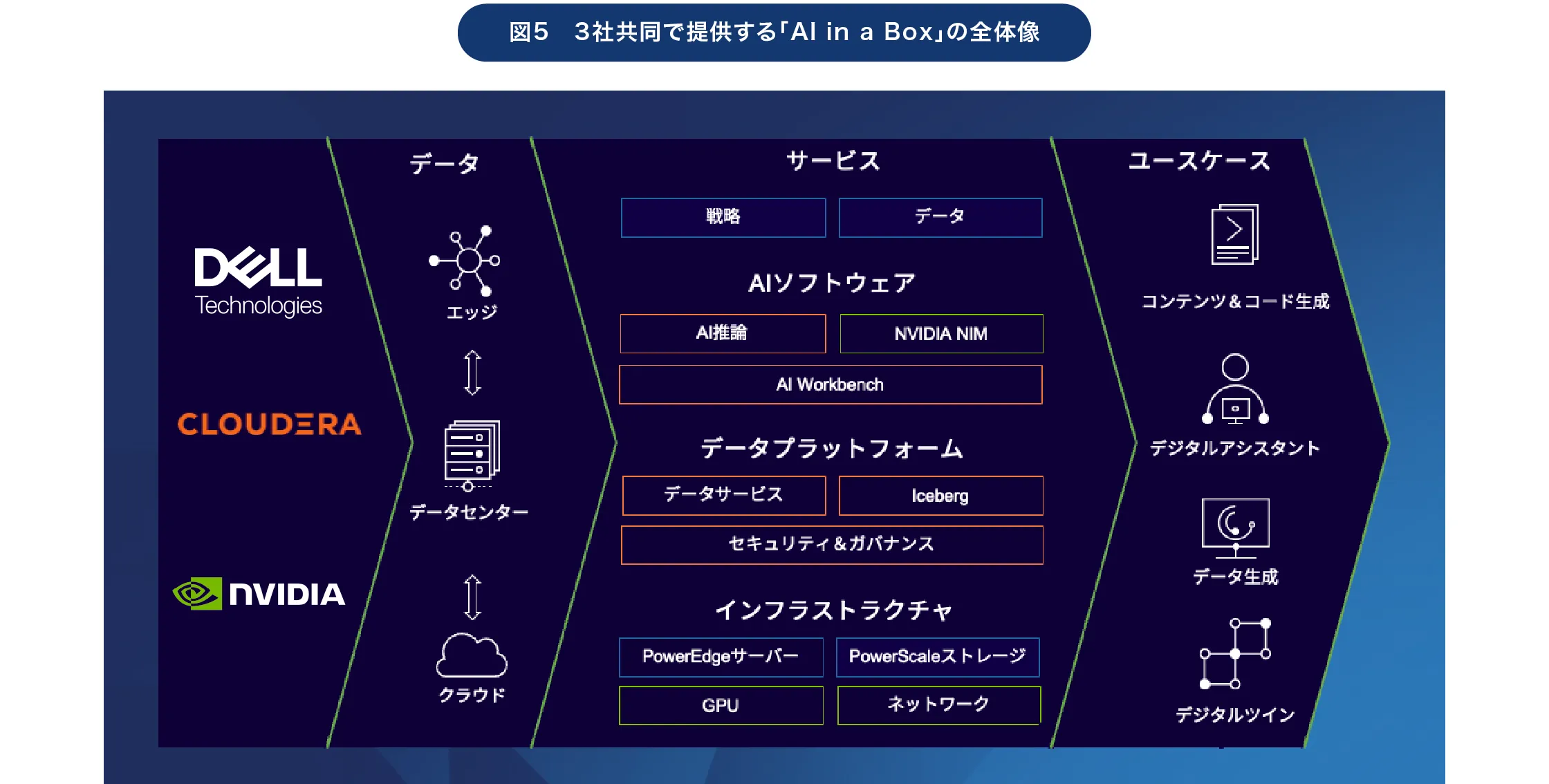
効率の高いLLMやそれを動かすためのソフトウエア環境、データ基盤、ハードウエアなどを、事前設計・検証した上で提供している。
また環境構築のみならず、導入前の戦略立案やユースケース策定なども支援するという
「AI in a Boxのコンセプトは2025年に発表しており、2026年2月から提供を開始しています。これによって、通常であれば2~3カ月かかるオンプレミスでのAI環境の構築が、数週間にまで短縮できるようになります。効率的なLLMとそれを短時間で実装・稼働できるソフトウエア環境、そしてこれらを動かすハードウエアが、事前検証された最適な形で提供されているからです。また、Cloudera社の製品は、我々デル・テクノロジーズの本社側システムにて利用していることは以前より公に公開されており、我々自身がその機能性を熟知しています」(堀田氏)
このような共同ソリューションがあれば、AIの業務実装に立ちはだかる4つの壁を一度に解消できる。これによりAI活用の「次のフェーズへのシフト」も、短期間で実現できるようになるという。
「既に日本国内でも、ある著名なカード会社様への導入が進んでいます。AI in a BoxはエンタープライズにおけるAI活用の課題解決に、高いレベルでフィットするソリューションになるはずです。スケーラビリティも高く、Tシャツサイズと呼ばれる小規模な構成からでも導入可能です。ぜひ多くの日本企業の皆様にご活用いただき、AIの業務実装を成功させていただきたい」と堀田氏は最後に語った。

よくある質問
AI基盤構築が進まない原因は?
AI基盤構築を進める企業がPoCから業務実装に進めない原因として、主に以下の「4つの壁」が挙げられる。
第1の壁:LLMの進化に伴うリソース・コストの急増
第2の壁:社内データのサイロ化によりAIに必要なデータを届けられない
第3の壁:データやAIを社外に持ち出せないというAI主権/データ主権への対応
第4の壁:オンプレミス環境でのAIインフラ整備の複雑さ
サイロ化した社内データをAIで活用する方法は?
社内データがサイロ化している場合、データを一箇所に集約するのではなく、「仮想的な統合」というアプローチが、AI基盤構築を進める上で有効である。
Cloudera SDXのようなソリューションを活用すると、各部門やクラウドに分散したデータをその場所に置いたまま、アクセス制御を一元管理してAIから横断的に参照できる環境を構築できる。データの移動が不要なため、リアルタイム性の低下や転送コストの問題も回避可能である。
オンプレミスでのAI基盤構築にはどれくらいの期間が必要?
オンプレミスでのAI基盤構築には通常、設計から稼働まで2~3カ月かかるケースが一般的である。ただしエヌビディア、Cloudera、デル・テクノロジーズの3社が共同提供する「AI in a Box」を活用することで、この期間を数週間にまで短縮できる。
また、小規模な構成(Tシャツサイズ)からの導入も可能であり、初期投資を抑えながら段階的に拡張することもできる。
関連リンクRelated Links
