ハイブリッドクラウド
求められる「戦略的なハイブリッド化」
カギを握る「Hybrid by design」とは
結果的にハイブリッド化しているだけの企業は多い
多くの企業がハイブリッドクラウドを実現できているかのように見える。だが、それは果たして戦略的に設計されたものだろうか。ビジネスの求めに応じ、SaaSやIaaSを散発的に追加していく中で、「結果的に」ハイブリッド化しているだけのケースは多いはずだ。
「その場合もオンプレミスとクラウドの両環境を有しているといえますが、リソースの重複や二重管理が発生し、ハイブリッドクラウドの真の価値を引き出すことが難しい状態になっています」と日本ヒューレット・パッカード(以下、HPE)の小川 大地氏は指摘する。
また、既存システムをクラウドにリフト(移行)したものの、その後のシフト(最適化)が進まず、かえって運用コストが上昇したり可用性が落ちたりすることも珍しくない。「結果、一部をオンプレミスに回帰する企業も増えています」と小川氏は続ける。
オンプレミスでシステムを使い続ける場合も、仮想化コストの高騰という問題が立ちはだかる。使い方によっては、仮想化ハイパーバイザーのライセンス費が以前の10倍以上になるケースもあるという。よほどの必然性がない限り、継続利用の予算申請を通すことが難しくなっているはずだ。
そこでHPEが提案するのが、ハイブリッド前提で全体設計を行う「Hybrid by design」というコンセプトである。要点は「ITインフラは常に外的要因に左右されると考える」こと。この考えのもと、企業・組織の戦略的なハイブリッドクラウド化を支えるのが「HPE GreenLakeクラウド」だ(図1)。
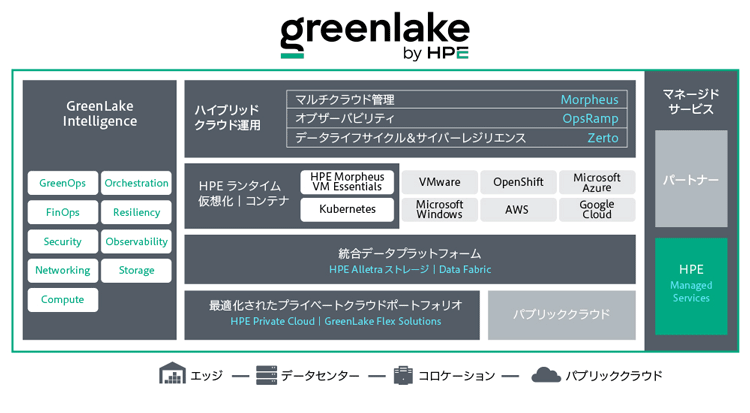
図1 HPE GreenLakeクラウド
ロゴも一新し、HPE以外の製品やパブリッククラウドも含めた、マルチベンダー・マルチクラウド対応の統合クラウドに成長した。今後提供されるAI機能「GreenLake Intelligence」にも期待したい
オンプレミス環境に設置したHPE製のサーバー、ストレージ、ネットワーク機器などのITインフラと、外部のパブリッククラウドサービスを一元的に運用できる。クラウドライクな従量課金型で使えるハイブリッドクラウドソリューションである。
IT部門がサービスプロバイダーとなって価値を提供する
中でも、戦略的ハイブリッドクラウド化のカギを握る機能が、一元管理を担うプラットフォームソフトウエア「HPE Morpheus Enterprise Software」だ(図2)。

図2 HPE Morpheus Enterprise Software
ユーザーはハイブリッドクラウド・マルチクラウドを統合ポータルからセルフサービス型で利用可能になる。これによってIT部門が“社内サービスプロバイダー”に変革可能にするのが魅力だ
「仮想マシンやKubernetesコンテナ、Webアプリ、パブリッククラウドなどを統合Web ポータル経由で利用できるようにします。また、セルフサービスや自動化、ガバナンス、部門向けの個別の利用料設定などの機能も備えています。これを使うことで、IT部門が “社内サービスプロバイダー”となり、会社のオンプレミスとパブリックにまたがるハイブリッドクラウド活用を統合的にマネージし、利用部門へサービス提供することが可能です」と小川氏は述べる。
また、HPE GreenLakeクラウドでは仮想化ハイパーバイザーの代替機能も提供されている。それが「HPE Morpheus VM Essentials Software」だ。日本企業ではあまり使用されていない高度かつ複雑な機能を省くことで、価格を大幅に抑制。既存環境からの移行により、仮想化コストを1/10にした企業もあるという。
「インフラやハイパーバイザーなどの下層部分の運用管理はメーカーに委ね、パブリッククラウドのような使用感を実現したいお客様には『HPE Private Cloud Enterprise』がおすすめです」(小川氏)。HPE GreenLakeクラウドにHPE Morpheus VM Essentials Softwareをパッケージ化し、HPE自身がフルマネージド型で運用に当たる。これであれば、利用経験のないハイパーバイザーでも安心だ。
なおHPEは、年次イベント「HPE Discover More AI 東京 2026」を2月19日に開催する。そこでは2025年に国内リリースされたHPE Morpheusブランドの製品を中心に、一連のハイブリッドクラウドソリューションが多数紹介される予定だ。戦略的なハイブリッドクラウド化を推し進めるための要点を、ぜひ現地で確認してもらいたい。
ネットワーク
AIを駆使した「Self-Driving」で
ネットワーク運用の新時代を切り開く
ネットワークの運用モデルは「AIネイティブ」へ
「現在の企業のIT担当者が直面している課題は、驚くほど共通しています。システムに問題が発生した際、解決まで一定の時間がかかるのは仕方ありません。ただ、その原因と対応について十分説明できないことが多いのです」とHPEの上田 昌広氏は指摘する。
例えば、障害が発生した際、原因がシステム環境のどこにあるのか特定できないケースは多い。あやふやな判断のもと、不要な障害報告書の作成やトラブルシューティングを繰り返すことで、ただでさえ足りない人的リソースを浪費している。本来業務や新規プロジェクトのローンチが遅れ、経営層からは「対応が遅い」と叱責される。結果、ITシステム全体に対する期待値が低下してしまう。
この負の連鎖を断ち切るため、注目すべきなのがネットワークだ。複雑化し、障害対応のボトルネックになりがちなネットワークの在り方を見直すことで、ITシステム全体の信頼性を取り戻す。
HPEが提唱しているのが、「Self-Driving Network」というAIネイティブなネットワーク運用モデルである(図3)。ネットワークインフラ各所でのAIによるデータの分散処理、およびクラウド上での分析によって、根本原因の特定と修復を自動化する。
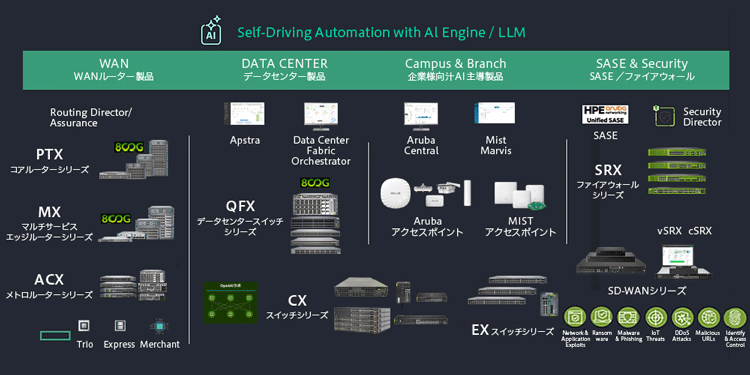
図3 HPE Networking製品ラインアップ
ジュニパーネットワークスの統合によって実現した全方位の製品ラインアップと、先進的なAIの活用によって次世代型のネットワークの実現を支援する
「システムのログのほか、ユーザーの体感に関わるデータも収集・分析することでオブザーバビリティを確保します。これにより、本当に使えるネットワークを自動的(Self-Driving)に維持します」(上田氏)。効果は大きく、トラブルチケットを90%、現地調査を85%削減したユーザー事例も数多くあるという。IT部門の運用負荷を大きく軽減できるだろう。
「Secure AI-native network」で安全性と運用効率を両立
もっとも、ネットワークの自動運転化は様々なベンダーが挑戦しているテーマでもある。HPEの強みは、元々サーバー、ストレージなどのインフラ製品を有しており、そこにアルバネットワークス、ジュニパーネットワークスなどのネットワークベンダーが加わることで実現された、包括的な製品ラインアップだ。データを網羅的に取得・分析できる環境があることが、ユーザーの体感を高める要になる(図3)。
さらにHPEは、エージェンティックAIやLarge Experience Model(LEM)といった新たな技術も活用することで、Self-Drivingネットワークの実現に向けて加速している(図4)。
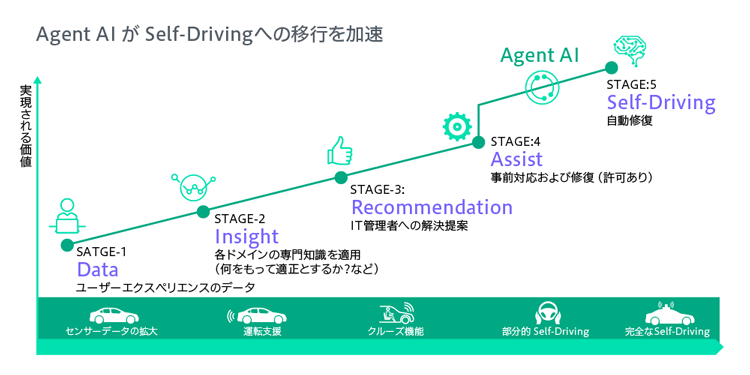
図4 Self-Driving Networkへの道
完全自律型の自動運転ネットワークは、かつて夢物語と思われていたが、エージェンティックAIにより実現可能なものとなった
エージェンティックAIがベンダー横断型で機器を監視し、データを分析することで、状況を速やかに可視化する。LEMは、大規模言語モデル(LLM)にユーザーの利用状況に関わるデータを付加することで、ユーザーの振る舞い予測を可能にする技術だ。障害が起こった際、自然言語で質問すると、原因を予測して提示してくれるほか、自動修復にまでつなげてくれるという。
「また、ネットワーク環境の構築で忘れてはいけないのがセキュリティーです」と上田氏は語る。これについては「Secure AI-native network」というコンセプトを提唱している。AI for Network ops(AIによる運用支援)と、Networks for AI workloads (AIのワークロードを守る)の2軸で多彩な機能を提供する。具体的には、SD-WAN、SASE、SSE、NAC、ファイアウォールによる多層防御やネットワーク自体の暗号化、ここまで紹介したAIによる振る舞い検知や自動化などが含まれるという。
「安全性と運用効率化を両立します。マルチベンダー環境でも一定の機器をまたいだ可視化・分析が可能ですが、HPE製品でネットワークを統合した場合は、より深いデータ取得と高度なオブザーバビリティを実現可能です」と上田氏は説明する。
HPE Discover More AI 東京 2026では、キャンパス&ブランチ向けのアクセスポイントやスイッチ、データセンター向けの1.6Tb相当の液冷スイッチなど、HPEのコンセプトを支える最新のネットワーク機器が多数展示される予定だ。こちらもチェックしてみてほしい。
AI
煩雑なインフラ選定はもう不要!
HPEが提案する「真のターンキーAI環境」とは
AI活用ニーズの変化により、迫られるインフラの変化
これまでSaaS型の生成AIモデルの利用が中心だったAI活用。だが、現在は「いかに実ビジネスのデータを生かすか」が多くの企業の焦点になっている。これにより、AIインフラにも発想の転換が求められている。
「機密データをクラウドに出せないという理由から、オンプレミスでインフラを構築するニーズが高まっています。また、パブリッククラウド上で高頻度に推論を行うと、かえってコストが増大します。このこともオンプレミス回帰の動きを後押ししています」とHPEの木村 拓氏は語る。
ただ、AIの学習/推論環境を自前で整え、さらに自社データを活用したAIチャットなどのアプリケーションを開発するのは簡単なことではない。AIインフラは、一般的なITインフラと要件が全く異なるからだ。
例えばハードウエアレイヤーでは、GPUの性能を最大化するための設計が必須になる。GPU間の通信を意識した広帯域なネットワーク、RDMA(リモートダイレクトメモリアクセス)およびGPU Direct Storageなど、従来の三層構造とは異なるアーキテクチャの知識・技術が求められる。
「ソフトウエアレイヤーではKubernetesがデファクトスタンダードです。分散技術を活用して複数のGPUサーバーをプール化し、AIモデルの展開およびファインチューニングを効率化しなければなりません。データエンジニアリング、アナリティクス、サイエンス、監視などを担う多様なソフトウエアも必要で、運用も複雑化しがちです」と木村氏は述べる。
ハードウエアもソフトウエアも必要なものを丸ごと揃える
HPEはこれらの課題の解決を支援している。大きな強みが、必要な環境のコンサルティングからGPUサーバーの調達、AI関連のシステム構築、ユーザー教育までをワンストップで提供できることだ。この強みを生かし、2025年に国内で提供開始したのが、「HPE Private Cloud AI」である(図5)。

図5 HPE Private Cloud AI
HPEのベストプラクティスに基づき、オンプレミスでのAI活用環境を丸ごと提供するプライベートクラウドソリューション。構築済みの状態で納品されるため、最短3カ月でAIを使い始められる
「NVIDIAと共同開発したフルスタックのAIソリューションで、ハードウエアからソフトウエア、運用・監視ツール、構築サービスまで必要な構成要素を丸ごと提供します。NVIDIA社とHPEのベストプラクティスに基づき、AIワークロード向けに最適化された数種類のプランから選択するだけで済むので、お客様が細かく中身を検討・設計する必要はありません」と木村氏は紹介する。
市場にある同様のソリューションは、ハードウエアの納品後に環境構築を開始するものも少なくない。そのため、「いつまで経ってもAI環境を使用できない」といったことが発生しがちだが、HPE Private Cloud AIは最短3カ月で、全機能が使える状態で納品される。これを同社は「真のターンキーモデル」と呼び、強みと位置付けている(図6)。
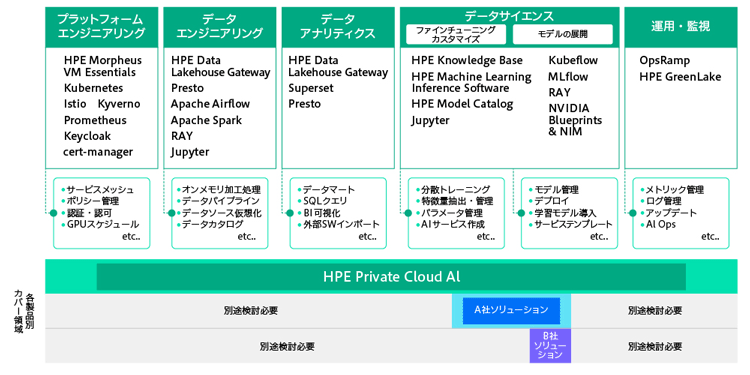
図6 AI活用に必要なソフトウエアも網羅的に内包する
オンプレミス環境でAIを活用する上で必須となる、データエンジニアリングやデータサイエンス、運用監視といった分野のソフトウエアも包含されている
さらに、特に厳格なセキュリティー要件を持つ企業に向けて、完全オフライン環境でも利用可能なエアギャップ対応バージョンも用意。金融機関、公共機関など、高度なデータガバナンスが必須になる顧客も利用できるようにしている。
HPE Discover More AI 東京 2026は、イベント名の通りAI関連セッションが目玉の1つとなる。そこでのメインテーマもHPE Private Cloud AIだ。木村氏自身が登壇し、コンセプトの復習をはじめ、新機能やアップデートの情報、事例の紹介など、技術を軸とした様々な最新情報を提供する。AIの現在地と未来を知る絶好のチャンスとなるだろう。




