「データとAIの民主化」を
インテリジェンス機能で実現
データ基盤の分散が加速して
各種データのサイロ化が課題
笹氏 ここ10年の間に、使用目的を果たすための処理がまだ実行されていないローデータを格納したデータレイクや、すでに社内の各システムで使われている処理済みのデータを収めたデータウエアハウスなど、対象データや構造が異なるデータ基盤を併用する企業が増えています。さらに「SaaS」をはじめとする社外のクラウド上に存在する多様なソリューションが加わるなど、データの所在地の分散が加速しています。
蓄積されたデータが「宝の山」であることに気づいても、それを有効活用するには、現時点では異なる基盤に存在するデータを集める必要があります。
しかし、データガバナンスやセキュリティ、データのサイロ化などの障壁があり、基盤統合に苦労するケースが少なくありません。移行作業には多くのコストやリソースも不可欠です。実際、複数の企業を買収して成長を続けているルネサス エレクトロニクスさんでは、グループ各社のデータ基盤が乱立し、データのサイロ化が顕著であったと聞きます。

ルネサス エレクトロニクス株式会社
情報システム統括部
シニアダイレクター
ナラキ・ジョナサン氏
ナラキ氏 おっしゃる通り、当社グループの旧データ基盤では、オンプレミスのデータウエアハウス上で数千を超えるジョブワークフローが稼働していました。各システム間でインターフェースを構築していましたが、エンドユーザーのニーズは「世界中の全データが統合された1つのプラットフォーム上で、データ分析とAIモデルの両方を利用できること」であり、それに応えるには新たなソリューションが必須でした。
当社のような製造業のデータ基盤では、生産管理などの機密情報を扱います。誰がどのように利用できるかルールを決めて制御できる、包括的なデータガバナンスとセキュリティ機能が備わっていなければ、いくら便利で優秀なデータ基盤であっても多くのユーザーに開放できません。
「データ統合」と「ガバナンスとセキュリティ」を両立するソリューションを探した結果、あらゆる形式の構造化/非構造化データや、機械学習モデル、ダッシュボードなどを、データ基盤を問わずにシームレスに管理でき、高性能で拡張性のあるガバナンスソリューションを提供するDatabricksに出会いました。
データ基盤の内製化が
時間とコストの低減に寄与
笹氏 Databricksの「データ・インテリジェンス・プラットフォーム」は、あらゆるデータを素早く加工して保管することはもちろん、データ可視化の仕組みなども備えています。BI(ビジネスインテリジェンス)ツールのダッシュボードなどで体系化された過去データをAI予測モデルに投入すれば、より精度の高い将来予測が可能です。
このようなデータ分析では、従来はプログラミング言語Pythonやデータベースの標準言語SQLを用いてデータを抽出していましたが、Databricksの「Genie」という機能を使えば、自然言語を用いて対話的にデータの検索、分析、可視化できます。
ナラキ氏 プログラミング言語を習得している一般ユーザーは少ないため、簡単な日本語や英語を入力すれば機械がコードに変換してくれるこのインテリジェンス機能はとても好評です。
今回Databricksを導入するにあたっては、データ基盤の構築・運用の内製化を重視しました。通常、プロジェクトを進める際は、企画書の作成に始まり、外部ベンダーへの見積もり依頼や契約、キックオフといった流れをたどるのが一般的です。一方、内製チームであれば、ビジネス部門の考えや背景を理解しているため、細かな説明や資料の準備といった手間が省け、すぐに着手できます。
笹氏 特にAIを活用するデータ基盤の構築・運用では、内製化は非常に重要です。外部のAIサービスだけに頼っていると、バージョンアップのたびに「これまで通り使えるのか、それともまた一から教育が必要なのか」を判断しなければなりません。しかし、社内で組んだAIモデルであればバージョンも内容も自社でコントロールできます。情報のアップデートやAIモデルの調整、ユーザーの対応などをエンド・ツー・エンドで社内完結でき、運用面での効率化が図れるのです。
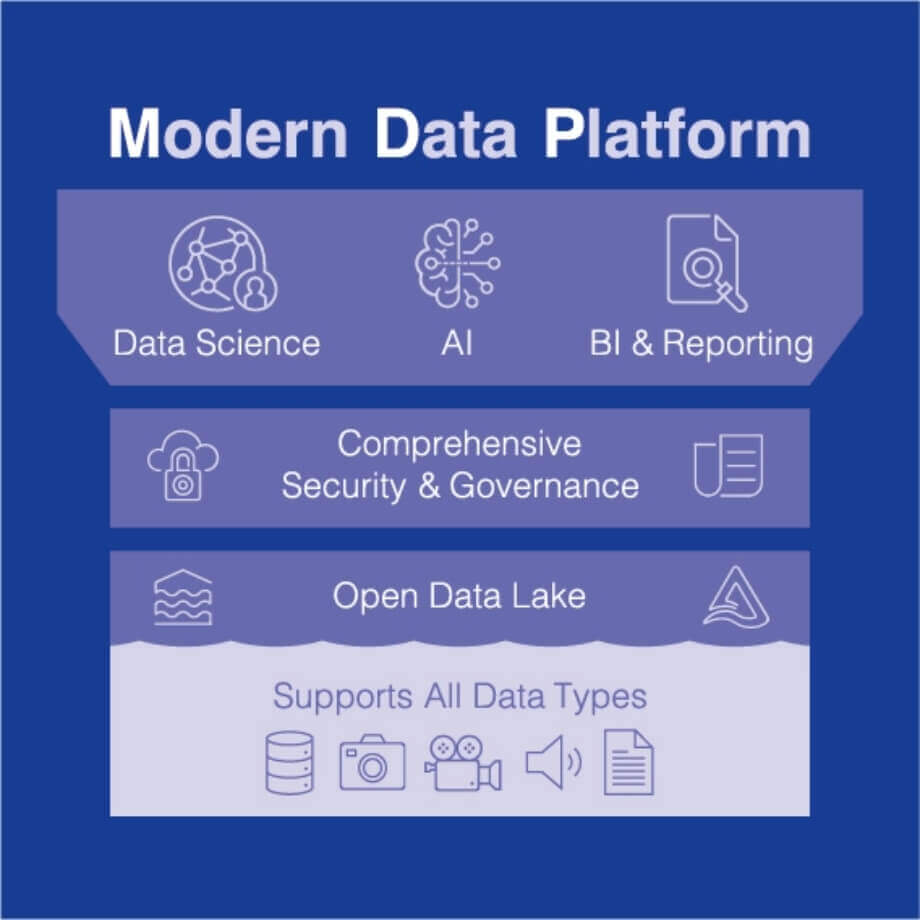
Modern Data Platform
ナラキ氏 内製化のためには、社員のトレーニングが欠かせません。当社は既存のデータ基盤を管理している社員であっても、クラウドの新しい技術に対するスキルを持ち合わせる人はほとんどいなかったため、DatabricksのILT(Instructor-Led Training)という研修コースをチーム全員が受講し、Databricksのコンサルタントの支援を受けつつアーキテクチャを設計して実装しました。
また、当社の新たなデータ基盤である「Modern Data Platform」のサービスを試験的に一部の社内ユーザーに提供した際には、データ分析やAI機能を使いこなしてもらうために200名超を対象にトレーニングを実施しました。
社内のAI モデルは業務に即した実用的な回答を出す点に重きを置いているため、社内の独自データを使って複雑な処理を行う分、時間は相応にかかります。しかし、ChatGPTやGeminiに慣れている社員には処理スピードが遅いと思われやすいため、トレーニングを通じて社内モデルへの理解を促していくことが重要だと感じました。
笹氏 「データとAIの民主化」には、ユーザーの育成が不可欠です。クラウドはオンプレミスと異なり、ニーズに応じてすぐに機能を拡張できます。また効率よく運用するには、コストとパフォーマンスのバランスを図ることに加え、経営層の理解も肝要ですね。
ナラキ氏 そこで当社は、2025年の初めにAI CoE( Center of Excellence)を設立しました。この事業は主に各部門の代表者を集めて全てのAI 関連アイデア・プロジェクトを可視化・集約しています。足元では2カ月間で100件近いアイデアが集まりましたが、その半分は似た内容であったため、統合して1つのソリューションとしてまとめました。

データブリックス・ジャパン株式会社
代表取締役社長
笹 俊文氏
また、既に社内で構築された生成AIツールを活用できるアイデアや、一部の機能追加で対応できるアイデアを優先的に採用しました。このような全社的な一括管理により、データとAIの活用スピードは保ちつつ、コストを抑えて効率的に開発を進めていけます。
笹氏 ルネサス エレクトロニクスさんをはじめ、国内ではイオンやNTTドコモ、全日本空輸、コスモエネルギーホールディングスなど、さまざまな分野の企業にDatabricksのソリューションをご利用いただいています。私たちはDatabricksの「データ・インテリジェンス・プラットフォーム」を通じて、ビジネスオペレーションの最適化やイノベーションの推進、意思決定の高度化に貢献していきます。