
ここ十数年間のAI(人工知能)民主化によって、データサイエンティストは激増した。その一方で、結果の出る組織を維持するには、階層化やリーダーシップ確立といった組織としての新しい取り組みが不可欠になってきている。AIチームの組織づくりで豊富な経験を持ち、自動化プラットフォームの提供を通じて通常業務を支援するDataRobot Japanの小川 幹雄氏が、データ活用に取り組む組織の最新トレンドと企業の対処法を語った。
データサイエンティストのトップランカーを集めて、2012年に米国で創業したDataRobot。AIプラットフォームを提供して企業のAI導入を支援し、2017年には日本法人を設立。その1年後に、日本企業100社へのプラットフォーム提供を達成した。2023年には大規模言語モデル(LLM:Large Language Models)のアプリケーションを容易かつ高速に開発できる機能をプラットフォームに追加し、生成AIのさらなる民主化を推進している。

DataRobot Japan
副社長 AI&サービス統括部長
小川 幹雄 氏
踊り場を迎えたAI組織の人材活用

同社の日本法人立ち上げメンバーの1人である小川氏は「ここまでAIやデータの民主化というメッセージを強調してきたが、人材教育の充実や生成AIの利用拡大によってステージが変わりつつあり、データサイエンティストの組織づくりも新たな局面を迎えています」と話す。DataRobotが生まれた2012年ごろからデータサイエンティストという職業が脚光を浴び、AIスキルを持つ少数精鋭の人材は引く手あまたで、先進企業のAI導入を後押ししてきた。
一方、2016年ごろから機械学習モデルの需要が急拡大し、データサイエンティストが持つスキルの一部が自動化していった。また、教育機関に学科が創設されたことで多くの人材が輩出され、ローコード、ノーコードといった初心者が扱える開発環境も増えた。その結果、データサイエンティストの数は増えたものの、入社後の再教育が必要な人材が集まってしまい、期待した成果が得られないトラブルを抱える企業も増えていると、小川氏は指摘する。
例えば、AIが花形業務と認識されたことで、マーケティング部が主導するDX(デジタルトランスフォーメーション)チームやシステム部主導のデータサイエンティストチームといった複数のチームが社内に立ち上がり、成果の取り合いで派閥争いになるケースだ。また、データサイエンティストのキャリア形成のトラブルもある。データ分析の研究的な仕事ができると思っていた社員が、実際は日々同じデータ処理の繰り返しばかりやロールモデルとなる社員がおらず将来が見いだせないことに不満を感じて、職場に見切りをつけて転職するケースも多いという。
この状況を打開するには「個々のデータサイエンティストの役割を明確にし、3階層に組織化して中間管理者を立て、チームのガバナンスを効かせていく必要があります」(小川氏)。組織体制の見直しにより、派閥争いの抑制や、長期的視野に立ったKPI(重要業績評価指標)の設定を実現し、若手からはキャリア形成の姿が見えやすくなる。
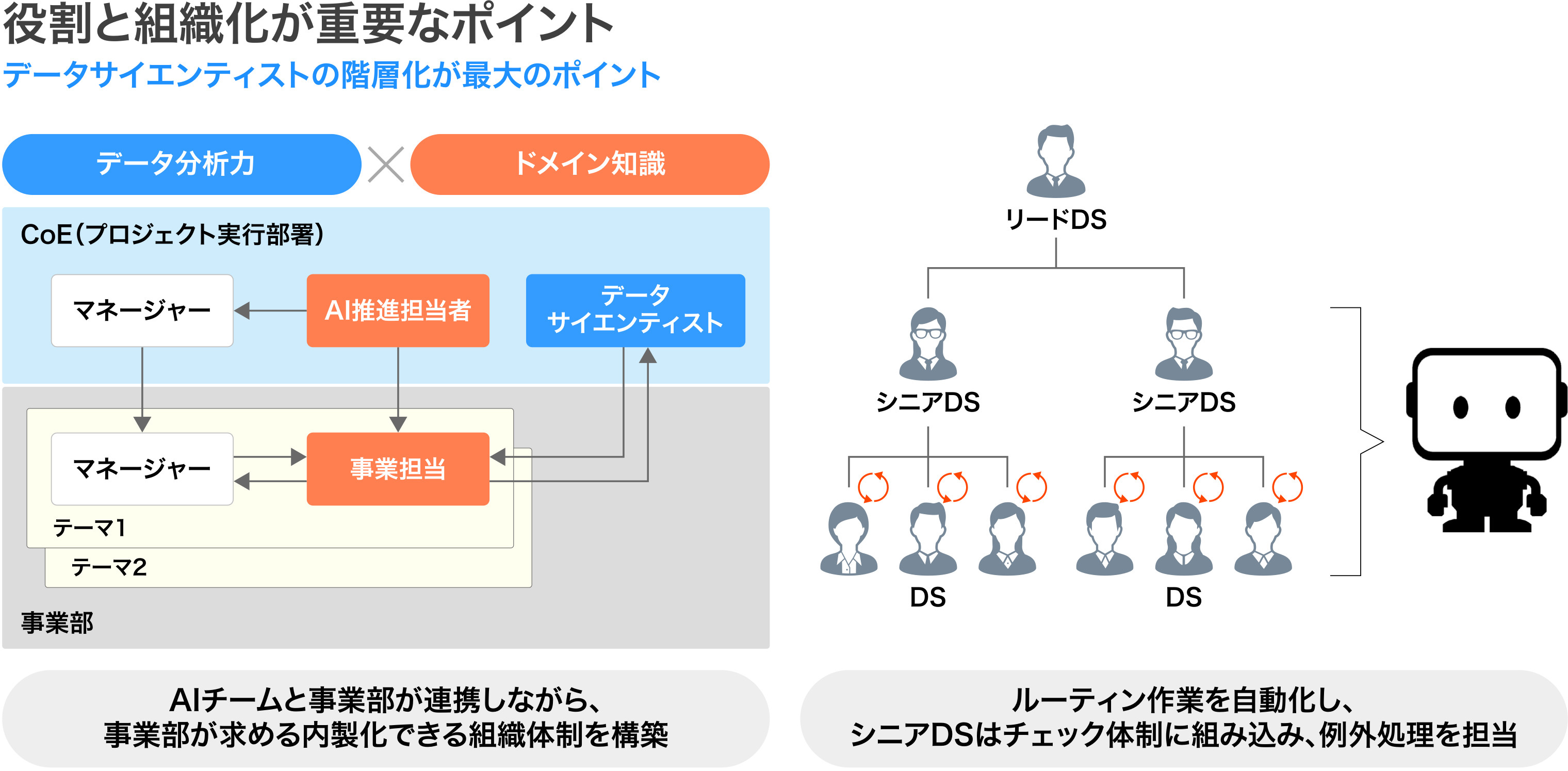
【画像をクリックすると拡大します】
単調業務は自動化でデータ人材のやる気を保つ
このように組織を階層化したら、それまで高度かつ多量のデータ分析を担っていた優秀な人材にはチェック役を任せて、中間管理者に昇格させる。また、自動化サービスを併用することで、退屈な日々のルーティンワークを削減すれば、若手社員が流出するリスクも低くなっていくだろう。
例えばAIモデルの運用業務では、まず蓄積したデータから不要部分を除去し、テーブル結合の後で特徴量を探索する。抽出した特徴量データから異常データを除外し(品質評価)、適切な補完・変換を加えて、モデリングとデプロイを行う。DataRobotはこの業務のほとんどを自動化するAIプラットフォームを提供している。
特徴量探索の工程は、線形系やツリー系などアルゴリズムの違いに応じてデータの処理が異なり、データサイエンティストの腕の見せどころといえるだろう。この処理は「AutoPrep」の機能で自動化できる。モデリングには機械学習を自動化する「AutoML」を活用し、デプロイは「MLOps」で自動化する。一方、不要データを除去する工程は、除去の理由がケースバイケースになるため、人がGUI(Graphical User Interface)操作で処理する仕様になっている。「人手の処理が多いと中間管理者のチェック業務が増えて負担がかかるが、大半を自動化すればその心配はなくなります」(小川氏)。
生成AIのガイドライン運用が必要に
2023年ごろから急拡大している生成AIにより、導入企業は新たな対策を迫られている。「重要なのは、生成AIはフェイクニュースの作成や犯罪手法の情報収集に利用できるなど、便利さだけでなく様々な危険もはらんだテクノロジーであり、誤った使われ方を防ぐ対策です」(小川氏)。
まずは利用ガイドラインを検討することだ。その際には日本と海外におけるAI利用のグレーゾーンの違いを知っておくことが重要となる。例えば米国は「ルールに書いてないことはやっていいというカルチャーで、グレーゾーンのギリギリまで攻めてきます」(小川氏)。一方、日本は「明文化されていることはやっていい」という考え方で、グレーゾーンを規定したガイドラインの手前で止まるのが一般的だ。
今後は、各企業が膨大な数の生成AIを導入する局面が想定される。すべてのAIモデルを同じように危険視すると機会損失につながるので、まずはそれぞれのリスクを3~4段階で評価する。その上で、高リスクのAIモデルには多くの制限をかけ、低リスクのモデルは制限を少なくするのがポイントだ。また「AIモデルには“賞味期限”があるが、作った本人は言わないこともあるので、中間管理者がチェックする必要があります」(小川氏)と語る。
こうした生成AIのリスク管理も自動化できる。例えばDataRobotのAIプラットフォームでは、ユーザーが聞いている質問など、生成AIごとに使われ方の状況を自動モニタリングし、問題があった時は自動的に深掘りする。使われ方の変化に対応できずに回答精度が劣化する、データドリフトの発生も自動モニタリングする。
小川氏は「自動化ツールの活用にとどまらず、チームのリーダーを明確にしてAI運用方針を固め、新人でも引き継げるように定型業務を簡素化することが、継続性に優れた組織づくりには大切だと思います」とアピールし講演を締めた。