2025年4月15日、AWS東京リージョンで大規模障害が発生した。可用性ゾーン(AZ)の主電源と予備電源の両方が遮断された結果、AZ内のAmazon EC2インスタンスや関連サービスに接続障害やAPIエラーが発生。AWSは障害発生から数分以内に対応を開始し、障害は約1時間で復旧したが、その間、多くのユーザーがサービスの停止や遅延の被害を受けた。一部のインスタンスやボリュームは、ユーザーによる手動での再起動や再構築が必要になったという。
「近年、クラウドのインフラ品質やSLAは大きく向上しています。モニタリングなどのツール群も拡充されており、ユーザー側でも細かな管理・運用が可能になりました。そのため『シングルAZ構成でも可用性は確保できる』と考えるお客様は多いようですが、残念ながらそれは誤解です」。そう語るのはサイオステクノロジーの西下 容史氏だ。同社は、2012年からAWSパートナーネットワークに参加しているソリューションベンダーである。
例えば、データセンター側の電源や空調などに起因する障害の可能性はゼロではない。AWS東京リージョンの大規模障害はそのことを象徴するできごとと言えるだろう。
クラウドユーザーは、これを教訓として「自分たちのシステムは自分たちで守る」方法を確立する必要がある。考えるべきポイントは大きく3つだ。
1つ目は、高可用性設計の責任範囲である。パブリッククラウドサービスは責任共有モデルに基づいてサービスを提供している。責任共有モデルとは、可用性や信頼性についてどこまでクラウド事業が責任を持ち、どこからユーザーが責任を持つかを定義したものだ。
基盤からアプリケーションまでを提供するSaaSはクラウド事業者の責任範囲が広いが、PaaSの場合はアプリケーションの責任をユーザーが持つ。基盤のみ利用するIaaSは、OS、ミドルウエア、アプリケーションまでがユーザーの責任範囲となる。「自由度が高いほどユーザー側の責任範囲も大きくなります。今回の障害は、クラウド基盤の物理トラブルがユーザーシステムに影響を及ぼしました。クラウドのインフラがどんなに高品質でも、ユーザー自身が責任範囲を把握して、システムに責任を持つことが大切です」と西下氏は言う。
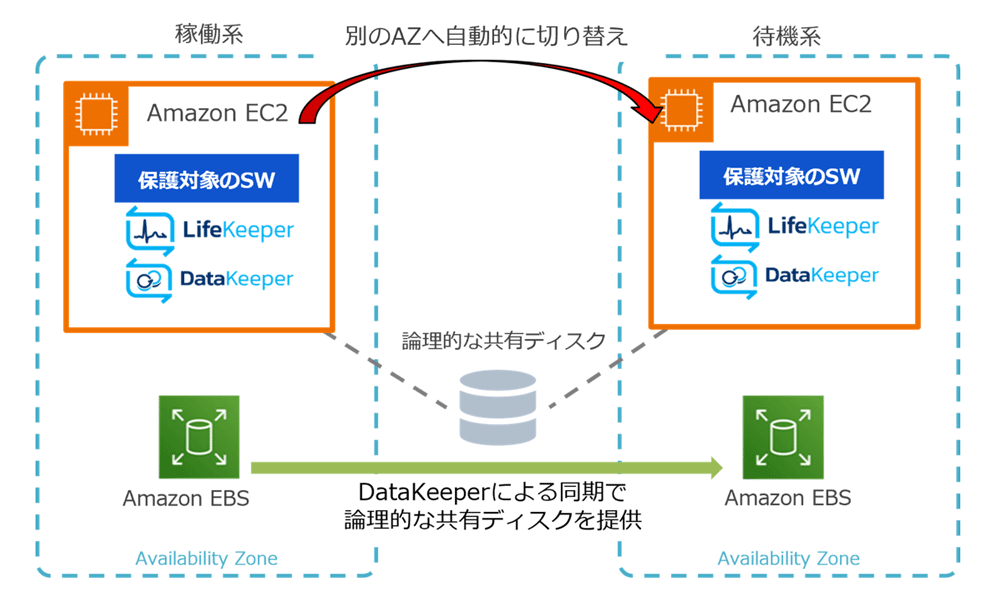
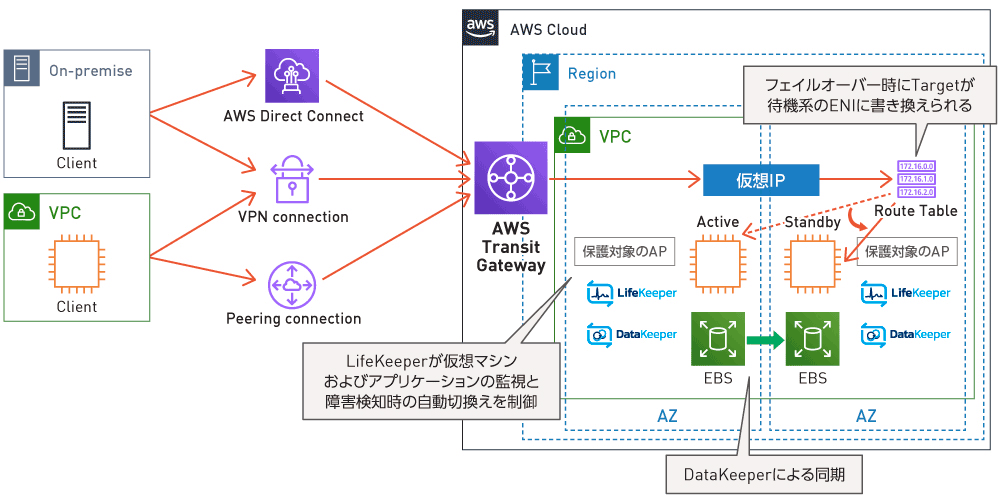
2つ目はAZ構成。今回の障害は多くのシステムが単一のAZに依存した構成だったことが被害の拡大につながった。マルチAZによる冗長構成をとっていれば、耐障害性や可用性を高められた可能性があるだろう。自社システムの構成を見直すことが肝心だ。
そして3つ目が自動復旧だ。障害発生時、人的オペレーションによる復旧対応では手間も時間もかかる。リソース状態やサービス稼働状況をリアルタイムに把握するとともに、復旧を自動化するような仕組みが求められる。「これにより、障害の早期発見と迅速な対処が可能になり、復旧時間を大幅に短縮できます」と西下氏は述べる。