
今から3~4年後にはFortune 1000企業における業務の40%がAIに置き換わる──。こうした予測が現実味を帯び始める中で、AIエージェントの導入を見据えた「データ管理」の重要性が急速に高まっている。AIをビジネスで真価を発揮し続けるには、常に質の良いデータを集めて管理し続ける基盤作りが需要になる。セールスフォース・ジャパンの松林晶氏は、データバリューチェーンのあるべき姿と、その実現に欠かせないデータマネジメントを支える具体的な機能群を紹介した。
AI Readyなデータ基盤作り
企業が取り組むべきステップとは

株式会社セールスフォース・ジャパン
インフォマティカ事業部 ソリューションエンジニアリング本部
アカウントソリューションエンジニア
松林 晶 氏
「AIが食べるのはデータです。品質の悪いデータを食べたら、AIも“食あたり”を起こします」――。セールスフォース・ジャパンの松林氏は冒頭に、分かりやすい表現でAIにとってのデータ品質の重要性を訴えた。
AIを活用した企業活動を継続するためには、AIに「品質の良いデータを継続的に供給し続ける」ことが大前提となる。もちろん品質だけではなく、センシティブなデータ(個人情報など)を無秩序にAIに渡してはならないという制約もある。松林氏は「データであれば何でもAIに与えていいわけではありません。AIを活用した企業活動にはデータマネジメント、つまり『データを準備する活動』が欠かせなくなります」と指摘する。
データ品質の担保と適切なアクセス制御(データマネジメント)を体系的に解決するために、セールスフォース・ジャパンが提唱しているのが「データバリューチェーン」という概念だ。データバリューチェーンの考え方を理解しやすくするため、松林氏は、①データを集める、②データの品質を改善する、③データの意味をわかるようにする、④データアクセス管理を行う――という4つのステップに分けたダイジェスト版を提示した。
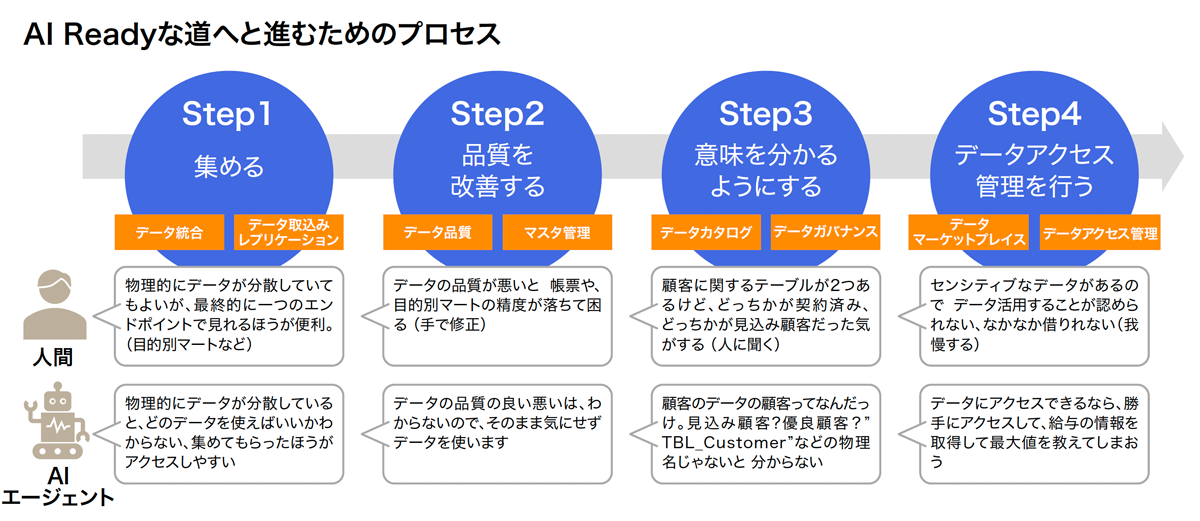
【画像をクリックすると拡大します】
収集や品質改善が可能なデータ管理基盤
人がデータを活用する場合、まず社内の各システムなどからデータを集めて「データレイク」や「データウエアハウス」にまとめる。データの品質に問題があれば手直しし、データがカタログ化されていない場合は担当者に聞くなどの手間が生じる。必要なデータが提供されなかったり、データが足りない状態であったりしても、どうにか分析しなければならない、というケースもあるだろう。
4つのステップそのものはAIのデータ活用にも同様に適用されるが、問題はAIが人のように「適切な判断」ができない点にある。松林氏は「AIはデータ品質の良し悪しがわかりません。略称などのテーブル名では、どんなデータが入っているかも判断できない。さらに、適切なアクセス管理をしなければ、無制限にデータにアクセスしてしまうこともあります。つまりAIを企業活動に活用するためには、データマネジメントが不可欠なのです」と強調する。
そこで、セールスフォース・ジャパンが提供するのが、データ収集からアクセス管理まで4つのステップすべてのデータバリューチェーンをカバーするソリューション「Intelligent Data Management Cloud(IDMC)」である。特に最近になって進化しているのが、ステップ①のデータ収集とステップ②のデータ品質の改善にかかわる機能だ。
例えば、ノ―コードによるドラッグ&ドロップでデータの収集ができ、AIエージェントに「SQLサーバーから顧客情報を集めてほしい」と自然言語で指示すれば、自動的にパイプラインを生成する。データ品質の改善については、プロファイリングというデータ品質改善チェックツールを用意しており、AIエージェントに「プロファイリングしてほしい」と指示すればデータ品質をスコア化します」と、松林氏は解説する。
3つのフェーズで活用を支援
セールスフォース・ジャパンは、IDMCを使い大きく分けて以下の3つのフェーズで、データ活用を支援することを推奨している。
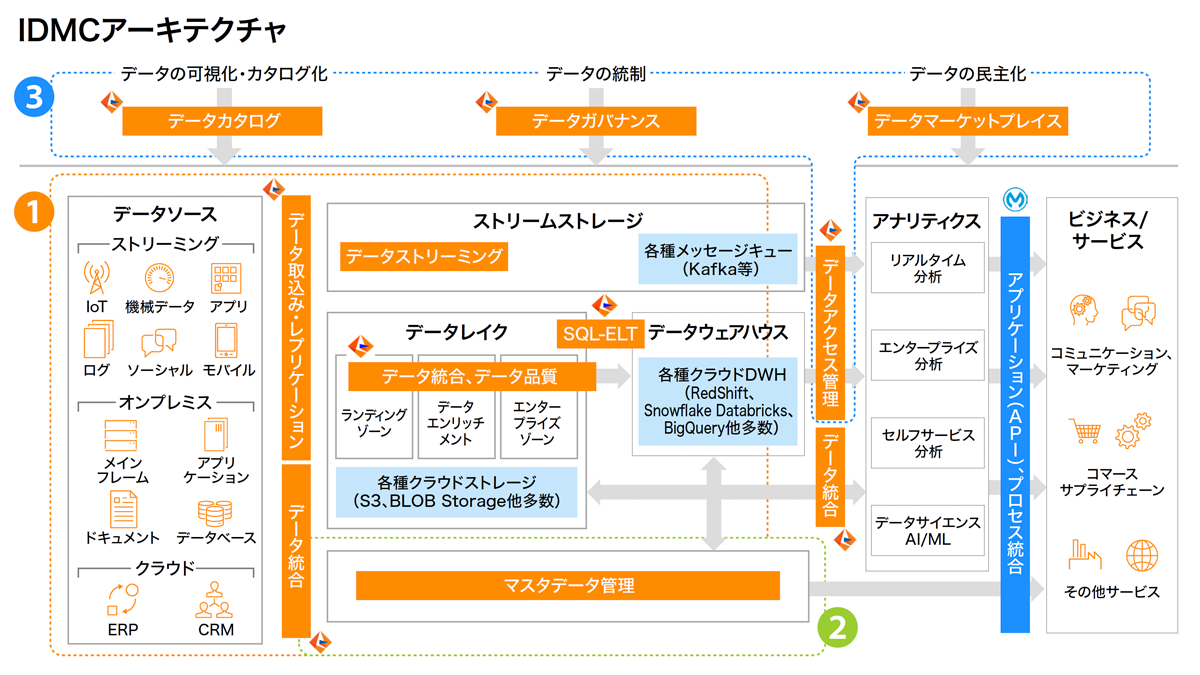
【画像をクリックすると拡大します】
フェーズ1:データを集める(データ統合・レプリケーション)
まず着手すべきは、散在するデータの統合だ。ETL(抽出・変換・ロード)やレプリケーションツールを用いて、オンプレミス/クラウドを問わず約300種類のコネクターで各種システムからデータを収集する。GUIベースでパイプラインを構築できるCDI(Cloud Data Integration)を使い、データプレビュー機能により手戻りの少ない効率的な開発が可能である。注目すべきは、前述した自然言語によるパイプライン生成機能である。松林氏は「北米では既に提供されており、日本での提供も視野に入れている」と自信をのぞかせる。
フェーズ2:データ品質を高める(データ品質・マスターデータ管理)
マスターデータをダイレクトにデータウエアハウスに投入するのではなく、まずはマスターデータを管理するMDM(Master Data Management)により、品質改善や名寄せを行い分析のためのマスターデータを整備しておく。「このマスターデータ管理によって、トランザクションデータとうまく紐付くようにすることが肝になります」と松林氏は強調する。
フェーズ3:活用基盤を整える(データカタログ化・ガバナンス・アクセス管理)
最後に、人間とAIの双方が利用できる基盤を整備する。例えば、「見込み顧客」と「優良顧客」の区別がつくようにカタログ化してメタデータを付与することで、人間もAIもデータの意味を正しく把握できるようになる。ガバナンス機能では、どのテーブルの、どのカラムが個人情報保護法などの法令等、レギュレーションに関連するのかをラベリングすることが重要になる。
その後に、データマーケットプレイス機能やアクセス管理機能で、データの安全な利用が実現する。松林氏は「これらの3つのフェーズに沿って進めている企業は、人もAIも品質のよいデータをきちんと管理しながら提供できている傾向にある」と主張する。
松林氏は「今日の講演で紹介した内容は、あくまでダイジェスト版に過ぎません」と前置きしながら、「人はもちろん、AIが自由かつ安全にデータにアクセスするためには、これらのデータマネジメントが欠かせません」と繰り返し強調した。
AIエージェント時代の本格到来を迎え、企業は今、データマネジメントの基盤づくりを急ぐべき時期にあるといえそうだ。
株式会社セールスフォース・ジャパン
https://www.informatica.com/ja/