自動運転の高度化に“データドリブン開発”が必須な理由(背景編)

自動運転の高度化に“データドリブン開発”が必須な理由(背景編)
先述の通り、レベル3以上の自動運転システムを開発しようとすれば、その走行シナリオの多様さ、システムの複雑さを考えると、試験車両を用いた実走行試験で必要な項目をすべて評価しようとするのは不可能だ。いきおい、仮想的な試験、つまりシミュレーション技術を活用せざるを得ない。
自動車業界ではこれまでもシミュレーション技術を活用してきた。ECUの試作品が出す制御信号に対して、実車両を模した出力信号を返して動作状況を試験する「HIL(Hardware in the Loop)」と呼ばれるシミュレーション装置はその代表的なものだ。しかし、自動運転用のECUは先の説明の通り、これまでのADAS用のECUや、エンジン制御用のECUに比べて格段に制御が複雑になっている。
このためECUの試作品が完成してから評価したのでは、欠陥が見つかった場合の対応に膨大な時間を要する。ECUを試作する前に、搭載するソフトウエアの段階で可能な限り完成度を高めておく必要があるのだ。それが「MIL(Model in the Loop)」、あるいは「SIL(Software in the Loop)」と呼ばれるシミュレーションテストの手法である。
変化する自動運転の検証プロセス
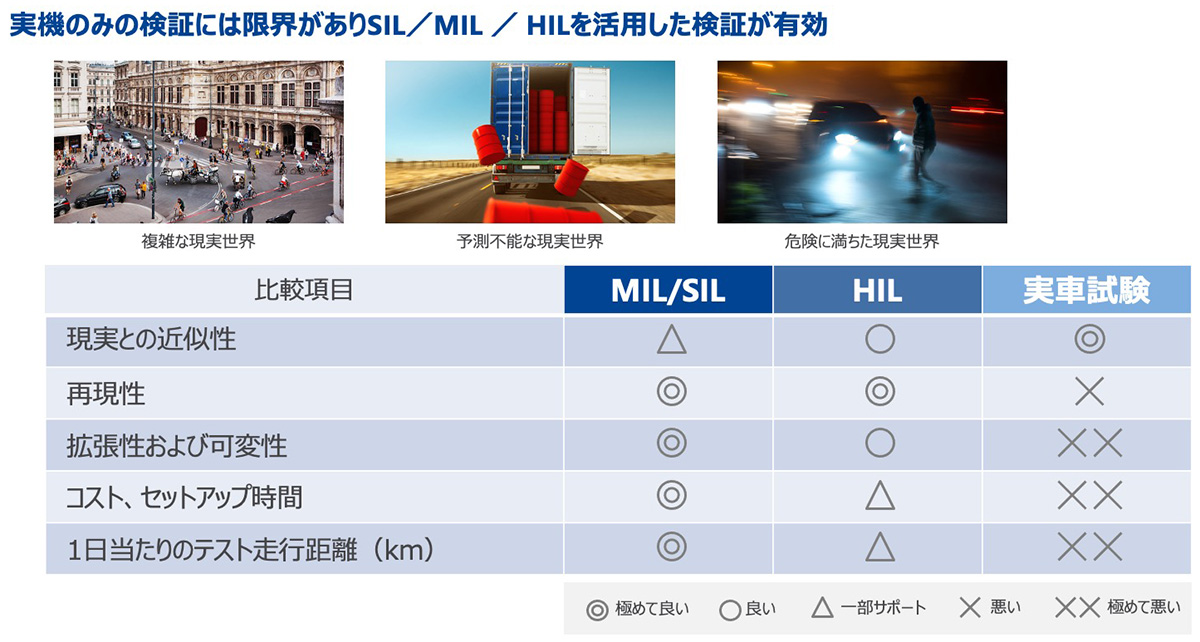
しかし、当然のことながらシミュレーション技術を活用すればそれで問題が万事解決ということではない。「ECU に搭載するソフトウエアの評価をシミュレーション環境で行うためには、各センサーが認識する外界の情報(周辺車両、人、信号、道路標識など)をすべてシミュレーション環境上で作り出し、車両の走行条件に応じた多数の走行パターン(シナリオ)を作成する必要があります」(山本氏)。こうしたシミュレーション環境の構築には、仮想環境といっても膨大な工数がかかる。
同社が提案する「データドリブン開発」は、このような手間のかかるシミュレーション環境の構築を大幅に効率化するものだ。まず実車テストで実際の道路を走行してデータを収集する。そして集めたデータを基に、周囲の物体の匿名化や情報のタグ付けを半自動で実行してシミュレーション評価のためのシナリオを作成、このシナリオを用いてECU向けのソフトウエアを評価(MIL/SIL)。同じシナリオを用いて、ECUの試作品を評価(HIL)することもできる。
dSPACEが手掛ける自動運転/ADAS開発プロセス

「開発の初期段階から最終段階まで同じシナリオを活用することで、複雑な開発を効率的に進めることができるのが特長です」と山本氏。次回は、このデータドリブン開発についてより詳しく解説したい。